


- What is Thematic Analysis?
- Advantages of Thematic Analysis
- Disadvantages of Thematic Analysis
- Thematic Analysis Examples
- How to Do Thematic Analysis
- Thematic Coding
- Collaborative Thematic Analysis
- Thematic Analysis Software
- Thematic Analysis in Mixed Methods Approach
- Abductive Thematic Analysis
- Deductive Thematic Analysis
- Inductive Thematic Analysis
- Reflexive Thematic Analysis
- Thematic Analysis in Observations
- Thematic Analysis in Surveys
- Thematic Analysis for Interviews
- Thematic Analysis for Focus Groups
- Thematic Analysis for Case Studies
- Thematic Analysis of Secondary Data
- Thematic Analysis Literature Review
- Thematic Analysis vs. Phenomenology
- Thematic vs. Content Analysis
- Thematic Analysis vs. Grounded Theory
- Thematic Analysis vs. Narrative Analysis
- Thematic Analysis vs. Discourse Analysis
- Thematic Analysis vs. Framework Analysis
- Thematic Analysis in Social Work
- Thematic Analysis in Psychology
- Thematic Analysis in Educational Research
- Thematic Analysis in UX Research
- How to Present Thematic Analysis Results
- Increasing Rigor in Thematic Analysis
- Peer Review in Thematic Analysis
- How to cite "The Guide to Thematic Analysis"
Thematic Coding
Thematic analysis is a qualitative research method widely used across various disciplines to identify, analyze, and report patterns within data. It plays a crucial role in providing a detailed and complex account of data. Similar to many other qualitative research methods like framework analysis, narrative analysis, and discourse analysis, the process of coding is fundamental to thematic analysis, serving as the bridge between raw data and the emergence of insightful themes.
This article will guide you through the essential steps of coding for thematic analysis, from understanding the purpose of coding to organizing codes efficiently. By offering a clear and concise overview of the coding process, we aim to equip qualitative researchers with the necessary tools for conducting their thematic analysis effectively.

What is the purpose of coding in thematic analysis?
Coding in thematic analysis serves several critical functions. First, it allows researchers to systematically sift through vast amounts of qualitative data—such as interview transcripts, observations, or written responses—to identify significant patterns or themes. By breaking down the data into manageable segments, coding transforms raw information into organized categories that are easier to analyze.
Second, coding facilitates the recognition of relationships between different data segments. As researchers assign codes to data, they might begin to notice connections, contrasts, and trends that were not apparent at first glance. This process is crucial for developing a deeper understanding of the data and for the subsequent identification of themes that capture the studied phenomenon.
Furthermore, coding facilitates the rigor and transparency of the analysis. A well-documented coding process allows other researchers to understand the steps taken to arrive at certain conclusions, thereby enhancing the credibility and rigor of the study. Coding is a methodical approach to qualitative analysis, providing a clear trail from the raw data to the final report.
Lastly, coding is not just about data reduction; it's also an interpretative act. Researchers engage with the data, applying their theoretical knowledge and analytical skills to discern subtle nuances and meanings. This interpretive aspect of coding is what allows thematic analysis to go beyond mere description to provide insightful interpretations of complex human experiences and social phenomena.

What should a codebook include?
When it comes to a codebook, thematic analysis requires a set of elements to facilitate coding qualitative data. It encapsulates not only the definitions of each code but also integrates rules for application, examples, and provisions for theme development, making it an indispensable tool for researchers. Crafting a codebook is an iterative part of coding, setting a structured path for qualitative data analysis and ensuring a uniform approach across the data set.
Central to the codebook are the definitions of the codes themselves. These are crafted with precision, providing researchers with clear guidance on when and how to apply each code to the data. This clarity is crucial for enhancing consistency in the data analysis process, thereby enhancing the overall trustworthiness and quality of the research findings.
Alongside these definitions, the codebook delineates specific rules for coding. These rules address potential challenges in coding, such as handling ambiguous data, coding data that might fit into multiple categories, and distinguishing between codes that are similar in nature.
Equally important are the examples included for each code. By illustrating how codes are applied to actual pieces of data, these examples serve as practical guides that clarify the definitions and rules, ensuring that researchers can apply the codes accurately and consistently.
As the analysis evolves, the codebook itself is designed to accommodate the emergence and definition of themes. This includes grouping codes under broader thematic categories and providing preliminary definitions and examples for these themes, thereby facilitating a deeper and more organized analysis of the data.
The dynamic nature of thematic analysis necessitates that the codebook also includes a section for revision history. This part of the document tracks the evolution of the codebook, documenting any changes or updates made throughout the analysis. This not only provides transparency but also aids in understanding the development and refinement of the coding scheme over time.
Furthermore, additional notes may be included to cover any other pertinent information that does not fit neatly into the aforementioned categories but is nevertheless crucial for the coding process. This could encompass reflections on the coding strategy, details about the coding environment, or the thematic analysis software tools utilized, offering valuable insights for the ongoing analysis or for other researchers who might use the codebook as a reference.

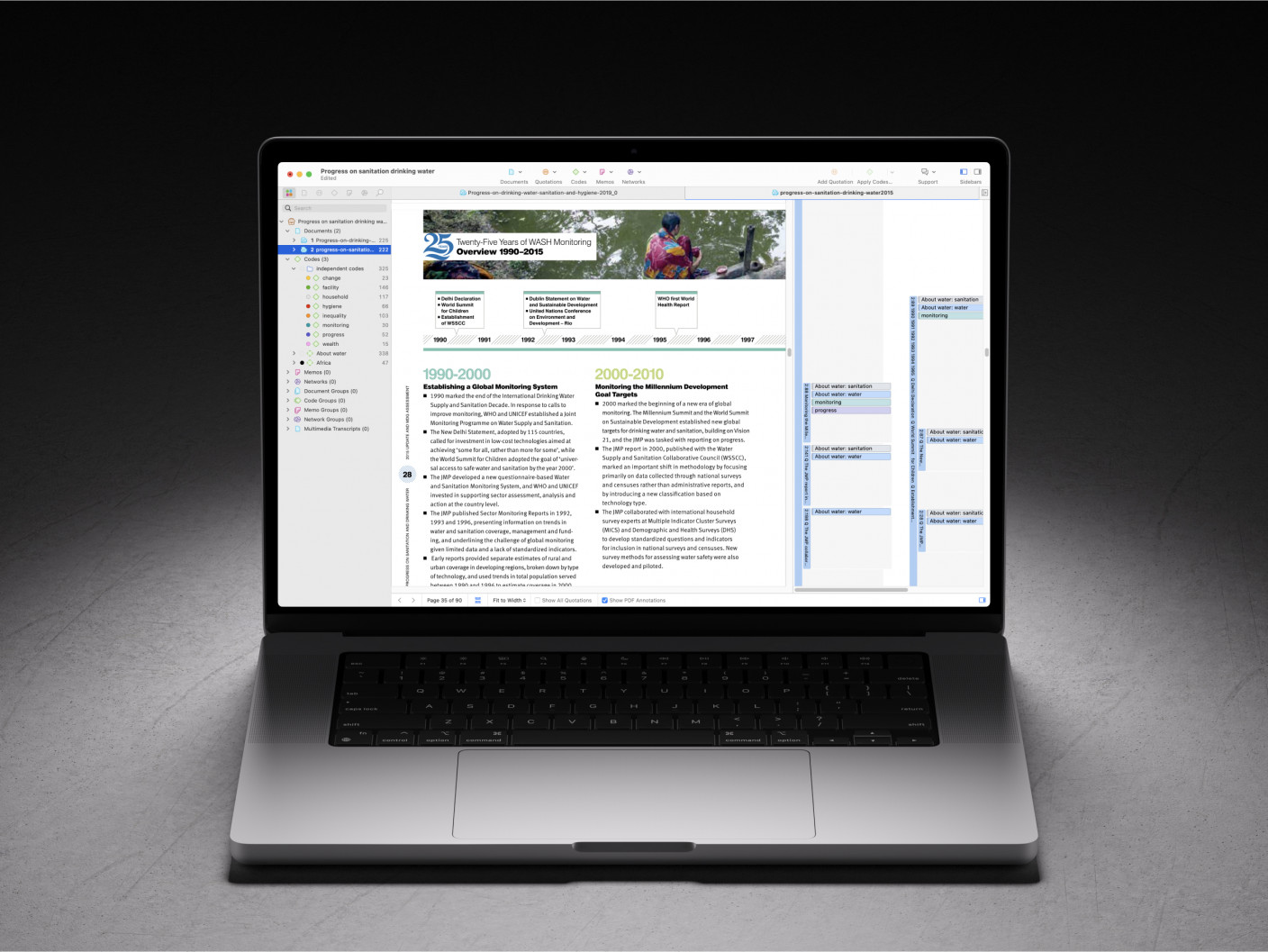
How should I code data for a thematic analysis?
Coding data in a thematic analysis process involves systematically identifying and labeling relevant parts of the data. This process is not just about tagging data with codes but also about engaging deeply with the content to discern underlying patterns and meanings. Coding lays the groundwork for the subsequent organization of codes and the generation of themes. It requires a meticulous and iterative approach, where data is reviewed multiple times to ensure that codes are accurately and comprehensively applied.
Below, we outline three key phases of the analysis process in thematic analysis: coding data, identifying patterns across data, and interpreting patterns across data.
Coding data
Coding the data refers to the process of reading through the data set (e.g., interview transcripts, field notes, documents, social media posts, etc.) to identify interesting excerpts and assigning codes that capture the essence of each data segment relevant to the research questions or objectives. At this stage, the aim is to code qualitative data as broadly and inclusively as possible, without worrying about the specificity or the potential overlap between different codes.
Coders should approach the data with an open mind, allowing the data itself to guide the creation of new codes. Codes can also emerge from more latent meanings present in the data, such that researchers can draw on their conceptual or theoretical understanding to create codes. This phase is exploratory in nature, with the goal of creating codes that capture the richness and diversity of the data.
Identifying patterns across data
After the expansive coding of the data, researchers can work with these codes to identify themes or patterns. This often also involves refining the codes and beginning to narrow down which are the most appropriate codes for the research questions or objectives. This phase requires the coder to make decisions about which codes to keep, combine, or discard.
The researcher can begin to identify patterns as they revise their codes: while a code might capture one idea, a theme brings together multiple ideas around a central organizing concept. At this stage, researchers begin creating provisional themes which will continue to be refined as the researcher progresses through their interpretive analysis.

Interpreting patterns across data
After engaging deeply with thematic coding and pattern identification, researchers can full develop their analysis by interpreting or making sense of the emerging patterns. It is important to revisit the data excerpts captured within each theme to ensure the theme effectively portrays the central organizing concept within the supporting data. This is also the point at which researchers name and define their themes, which can involve revising, combining, or even discarding themes; the objective is to have a set of themes that that tell a coherent and meaningful story about the data.
The researcher's subjective experience plays an important role in interpreting patterns as well, and researchers can critically reflect on how and why they make their interpretations. Fleshing out the interpretation of patterns and themes also relies heavily on writing up the analysis, as putting one's thoughts into words often clarifies new insights, exposes inconsistencies, and can effectively bridge key findings and supporting data.

How do you organize codes in a thematic analysis?
Organizing codes is a critical step in thematic coding. It involves sorting, grouping, and categorizing codes into meaningful clusters that facilitate researchers' interpretation and development of themes.
This is where the researcher begins to see beyond individual data points and starts to understand the broader patterns and relationships within the data. It requires a thoughtful and iterative approach, constantly refining the organization of codes to ensure that they represent the data and align with the research objectives.
Here, we explore three essential strategies for organizing codes in thematic analysis: creating thematic maps, using code hierarchies, and iterative re-coding.
Creating thematic maps
Thematic maps are visual representations that illustrate the relationships between codes and potential themes. They help researchers move from a collection of codes to a structured understanding of how these codes interconnect and form broader themes. Creating a thematic map involves arranging codes based on their conceptual similarities and identifying the overarching themes to which they contribute. This visual tool is particularly useful for seeing how individual codes can combine to form a coherent narrative within the data. It also aids in identifying any gaps or overlaps in the coding.
Using code hierarchies
Code hierarchies involve organizing codes into a structured format, where broader categories encompass a set of related sub-codes. This approach helps in managing the complexity of the data by breaking down broad themes into more specific, manageable elements. Hierarchies can clarify the relationships between codes, indicating which are central themes and which are supporting or subsidiary. By establishing a hierarchical structure, researchers can more easily navigate their codes and refine their analysis, ensuring that each code is placed within a meaningful context.
Iterative re-coding
Organizing codes is not a one-off task but an iterative process that evolves as the analysis deepens. Iterative re-coding involves revisiting and potentially re-organizing the codes multiple times throughout the analysis. This may include merging similar codes, splitting broad codes into more specific ones, or discarding codes that no longer seem relevant. Each round of re-coding refines the organization of codes, making the eventual themes more robust and grounded in the data. This process ensures that the final themes reflect the complexities and richness of the data, contributing to a more nuanced and insightful qualitative research analysis.