
Creating a Codebook for Qualitative Research

- Introduction
- Codes in qualitative research
- What is a qualitative codebook?
- Why should you create a codebook for qualitative research?
- What should a codebook include?
- Tools for creating a qualitative research codebook
Introduction
Qualitative data analysis often requires a robust coding framework to efficiently and systematically draw insights from otherwise unstructured data. Rich analysis depends on a rigorous approach to coding, but there are many challenges in the way of meeting this task and addressing your research question. So how can you ensure consistency of coding in your project?
There are many tools and methodological approaches to ensure the reliability and validity of your research, but this article will address the idea of the qualitative codebook. In many ways, it's little more than a simple reference to describe your codes, but the utility of a codebook is potentially immeasurable if it establishes the necessary research rigor that persuades your audiences.

Codes in qualitative research
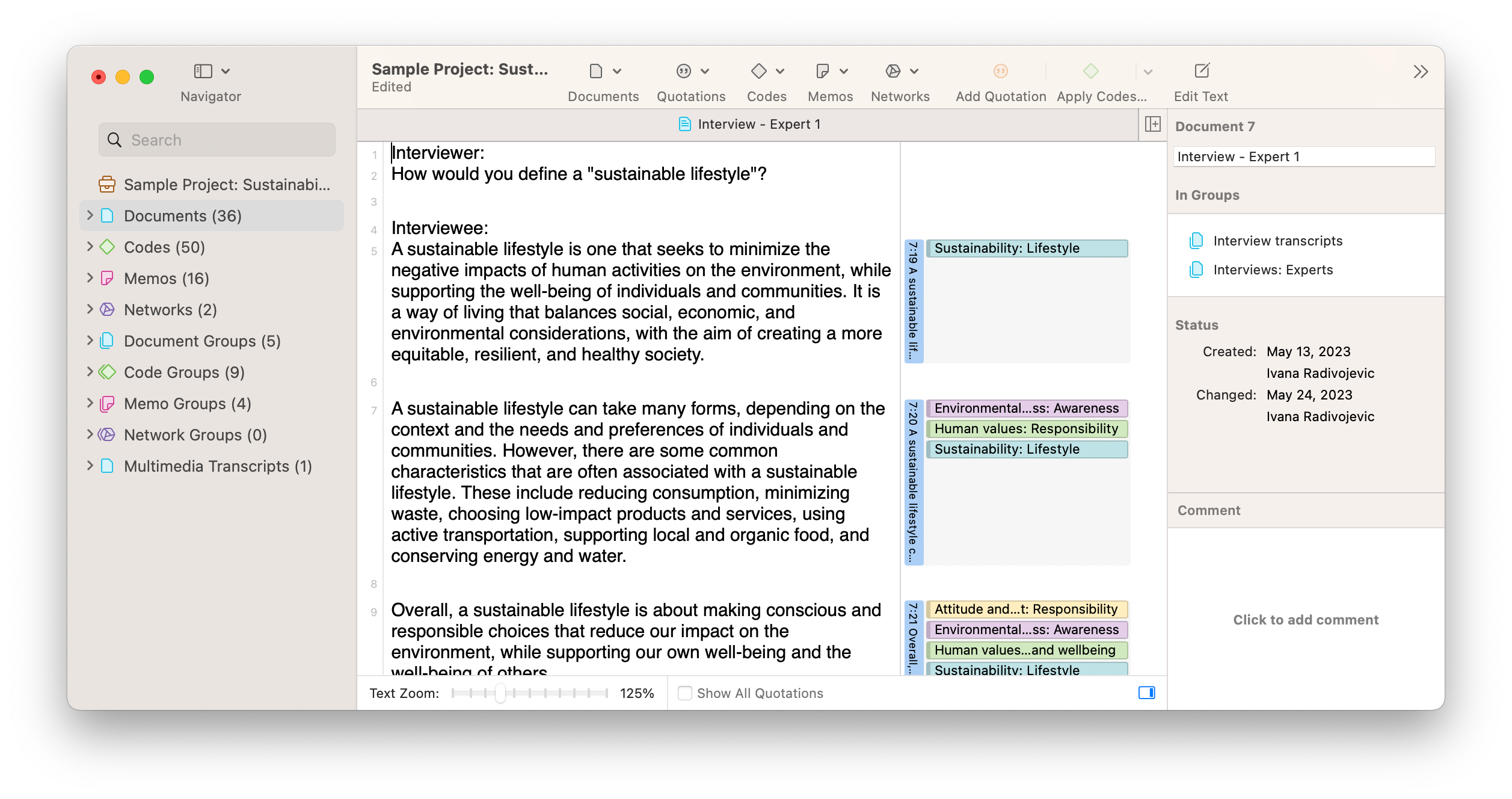
Qualitative coding is simply the process of applying short labels to qualitative data within a research project in order to bring structure to the information collected for a study. Applications of codes to qualitative data can make data easier to understand and analyze.
Codes have thus become an integral part of qualitative research that collects data from interviews, focus groups, survey questions, and other methods that generate unstructured data. These codes become the basis for how researchers interpret data and present findings to their research audience.
Considerations for coding
The challenge, however, is ensuring that the coding process is as systematic and rigorous as possible to ensure consistency across any given research project. As human researchers, our view of the data and, thus, our application of codes is inevitably subjective and is bound to change over time and across circumstances, which can be consequential when the data set is large and takes time to fully code.
The difficulties are compounded when multiple researchers are involved. When researchers look at the data in fundamentally different ways, the application of the coding framework is bound to differ from person to person. A rigorously conducted qualitative study that employs coding should have some degree of standardization regarding what codes mean and how they are applied to the data.
What is a qualitative codebook?
A codebook aims to provide standardization to research. It is simply a reference of the codes used in the research and the supporting details to describe what the codes are intended to represent. This can be in the form of a table, document, or integrated in a qualitative data analysis software, such as using the code comment spaces in ATLAS.ti.
Despite its simple role, its utility cannot be overstated in qualitative research. In the social sciences, the understanding of concepts and phenomena is subjectively constructed and is bound to differ depending on the researcher, the subjectivities they hold, and the theoretical or conceptual backgrounds informing their interpretations. A codebook describing those concepts is a concrete resource that researchers can refer to when there are any ambiguities about the meaning of the data.
Note that this does not mean that researchers and their respective audiences cannot disagree about the meaning of phenomena in the social world. Rather, a concrete reference in a codebook provides a clear record of the researchers' thinking about the data and the findings they generate so that there is at least a common understanding from which discussion can take place.

Why should you create a codebook for qualitative research?
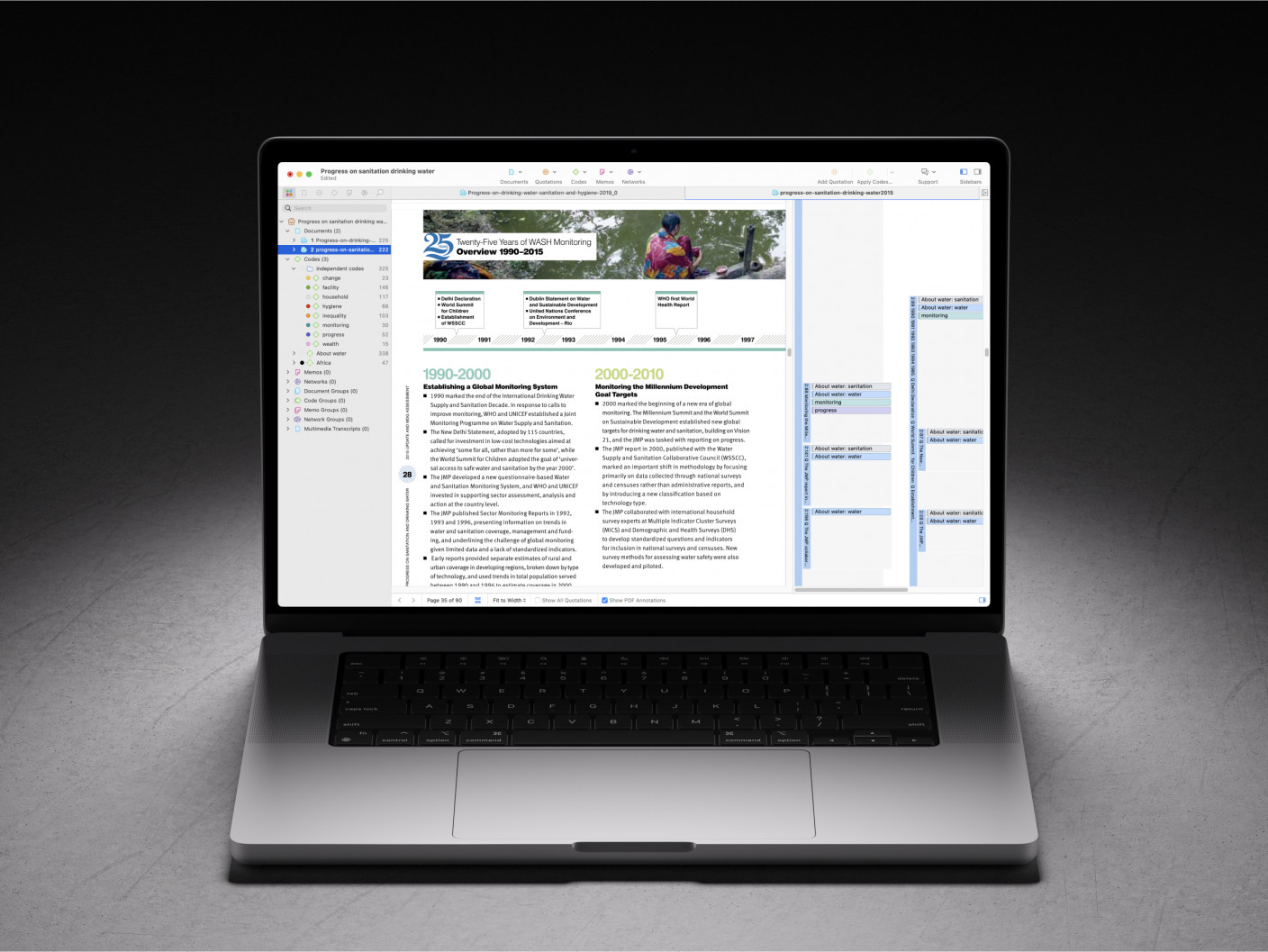
When working with multiple coders, qualitative data analysis relies on a consistent application of codes to your data. Consider a survey data file with thousands of records including open-ended responses divided among the members of your research team. Each of these coders is bound to have a different understanding of the coding process.
Given these circumstances, a robust qualitative codebook serves a number of purposes, which we will outline in this section. Transparency is the common thread across all of these different strands, as a clear record of the coding process allows the research audience to understand and believe the findings generated from the study.
Ensuring consistency across coders
As mentioned previously, one common role of a codebook is to provide a concrete resource for coders in a project to rely on when applying the coding framework to the data. Consider words like "relaxing," "entertaining," and "beneficial," all of which are bound to mean different things to different people.
A good codebook describes each of these terms if they are used as codes in a qualitative project. The goal of such description is to provide a standard meaning relevant to the data being coded rather than a universally applicable definition. This standard is aimed at fostering consensus among the coders regarding how to apply codes to the data.

Focusing data collection
A qualitative research codebook can also direct your data collection efforts by listing categorical variables that your research team should look for while in the field. This can help avoid the possibility of missing data by pointing out the salient details to observe or capture in data collection.
Keep in mind that this does not preclude an inductive coding approach, as a codebook with a set of initial codes can serve merely as a starting point for fieldwork research. Indeed, new codes can still be created during the course of research. A codebook helps by providing a basic foundation where all researchers are on the same page in terms of what data to collect.

Providing a transparent record
Research papers and presentations are as persuasive as the evidentiary warrants they provide to explain the assertions generated from the analysis. This means that presenting research findings in a transparent manner depends on outlining how the findings were reached.
In qualitative research, this often requires presenting how codes were created and applied to the data. This is why a codebook can and should be an important reference to researchers not only during the course of research but also when persuading audiences about the validity of their findings.

What should a codebook include?
As the goal is to create a useful reference for your coding framework, it's important to think about what elements are most useful to include in a codebook.
Codes
Codes are meant to be as short and descriptive as possible. A good code or variable label should be informative enough to tell researchers what the code is labeling while being brief enough so it is not obtrusive to reading the data.
Good code names rely on a proper balance between these two objectives. Coders should be able to quickly look at a list of codes to choose from, relying on the other elements of information for each code as necessary.
Code definitions
Your code definitions will invariably be more extensive than the code names themselves. These descriptions are especially useful if the code names are ambiguous enough that the meaning cannot be directly inferred.
For example, think about the word "diet." If it is used as a code, does it refer to a plan to lose weight (e.g., "a diet involving intermittent fasting") or a more general food regimen (e.g., "a diet of meat and potatoes")? You might be able to infer which one is used depending on the research question, but a extended description of the code can help clarify any ambiguities during coding.
Category codes
Grounded theory research and inductive research develop theory hierarchically, while deductive research relies on existing theoretical frameworks to break down complex phenomena into smaller, constituent elements or actions. Whatever the approach, a robust coding process relies on the hierarchical nature of codes distinguishing between sub-codes and the larger categories and themes that group them together.
As a result, the codebook should list these codes according to what categories they belong to. This organization helps makes the search for the relevant codes to apply to the data easier for coders in your project.
Data exemplars
Another good way to illustrate the meaning of codes is to provide representative examples of each code from the data. In cases where simple descriptions are not enough, examples of data segments that abundantly illustrate the ideal application of each code can provide the necessary clarity to your project team.
Co-occurrences and related codes
Especially in social science research, concepts and phenomena represented by codes are inevitably related to each other. Sometimes, codes that are related to each other in some way may not belong to the same part of your code hierarchy. In these cases, it is useful to list each related code and where they are located in the codebook for quick reference.
Tools for creating a qualitative research codebook
A codebook is a useful tool on its own, but its creation and development will depend on the use of other tools common in a qualitative study.
Data analysis software
Qualitative analysis software like ATLAS.ti is invariably the main source for your coding process, as it helps you keep track of where in the data each code is applied. ATLAS.ti's Code Manager lists all of the codes in your project so you can sort them alphabetically and hierarchically. The various search and analysis tools in ATLAS.ti can help list useful examples, identify important co-occurrences, and provide pathways for easily defining each and every code. The comment space available for each code provides the perfect place to write out code definitions, because coders can always easily see the code definitions while coding the data. You can also easily export your codebook to share it with others or import it into other projects.
Spreadsheet software
You can use ATLAS.ti to export your coding framework in the form of a spreadsheet. This spreadsheet can be used in a program like Microsoft Excel or a collaboration service like Google Sheets to develop your codebook further. Real-time collaboration on your codebook helps develop consensus among members of your team as they apply the coding framework to the data.

