
Document Analysis - How to Analyze Text Data for Research

- Introduction
- What is document analysis?
- Where is document analysis used?
- How to perform document analysis
- What is text analysis?
- ATLAS.ti as text analysis software
Introduction
In qualitative research, you can collect primary data through surveys, observations, or interviews, to name a few examples. In addition, you can rely on document analysis when the data already exists in secondary sources like books, public reports, or other archival records that are relevant to your research inquiry.
In this article, we will look at the role of document analysis, the relationship between document analysis and text analysis, and how text analysis software like ATLAS.ti can help you conduct qualitative research.

What is document analysis?
Document analysis is a systematic procedure used in qualitative research to review and interpret the information embedded in written materials. These materials, often referred to as “documents,” can encompass a wide range of physical and digital sources, such as newspapers, diaries, letters, policy documents, contracts, reports, transcripts, and many others.
At its core, document analysis involves critically examining these sources to gather insightful data and understand the context in which they were created. Research can perform sentiment analysis, text mining, and text categorization, to name a few methods. The goal is not just to derive facts from the documents, but also to understand the underlying nuances, motivations, and perspectives that they represent. For instance, a historical researcher may examine old letters not just to get a chronological account of events, but also to understand the emotions, beliefs, and values of people during that era.
Benefits of document analysis
There are several advantages to using document analysis in research:
- Authenticity: Since documents are typically created for purposes other than research, they can offer an unobtrusive and genuine insight into the topic at hand, without the potential biases introduced by direct observation or interviews.
- Availability: Documents, especially those in the public domain, are widely accessible, making it easier for researchers to source information.
- Cost-effectiveness: As these documents already exist, researchers can save time and resources compared to other data collection methods.
However, document analysis is not without challenges. One must ensure the documents are authentic and reliable. Furthermore, the researcher must be adept at discerning between objective facts and subjective interpretations present in the document.
Document analysis is a versatile method in qualitative research that offers a lens into the intricate layers of meaning, context, and perspective found within textual materials. Through careful and systematic examination, it unveils the richness and depth of the information housed in documents, providing a unique dimension to research findings.

Where is document analysis used?
Document analysis is employed in a myriad of sectors, serving various purposes to generate actionable insights. Whether it's understanding customer sentiments or gleaning insights from historical records, this method offers valuable information. Here are some examples of how document analysis is applied.
Analyzing surveys and their responses
A common use of document analysis in the business world revolves around customer surveys. These surveys are designed to collect data on the customer experience, seeking to understand how products or services meet or fall short of customer expectations.
By analyzing customer survey responses, companies can identify areas of improvement, gauge satisfaction levels, and make informed decisions to enhance the customer experience. Even if customer service teams designed a survey for a specific purpose, text analytics of the responses can focus on different angles to gather insights for new research questions.
Examining customer feedback through social media posts
In today's digital age, social media is a goldmine of customer feedback. Customers frequently share their experiences, both positive and negative, on platforms like Twitter, Facebook, and Instagram.
Through document analysis of social media posts, companies can get a real-time pulse of their customer sentiments. This not only helps in immediate issue resolution but also in shaping product or service strategies to align with customer preferences.
Interpreting customer support tickets
Another rich source of data is customer support tickets. These tickets often contain detailed descriptions of issues faced by customers, their frustrations, or sometimes their appreciation for assistance received.
By employing document analysis on these tickets, businesses can detect patterns, identify recurring issues, and work towards streamlining their support processes. This ensures a smoother and more satisfying customer experience.
Historical research and social studies
Beyond the world of business, document analysis plays a major role in historical and social research. Scholars analyze old manuscripts, letters, and other archival materials to construct a narrative of past events, cultures, and civilizations.
As a result, document analysis is an ideal method for historical research since generating new data is less feasible than turning to existing sources for analysis. Researchers can not only examine historical narratives but also how those narratives were constructed in their own time.

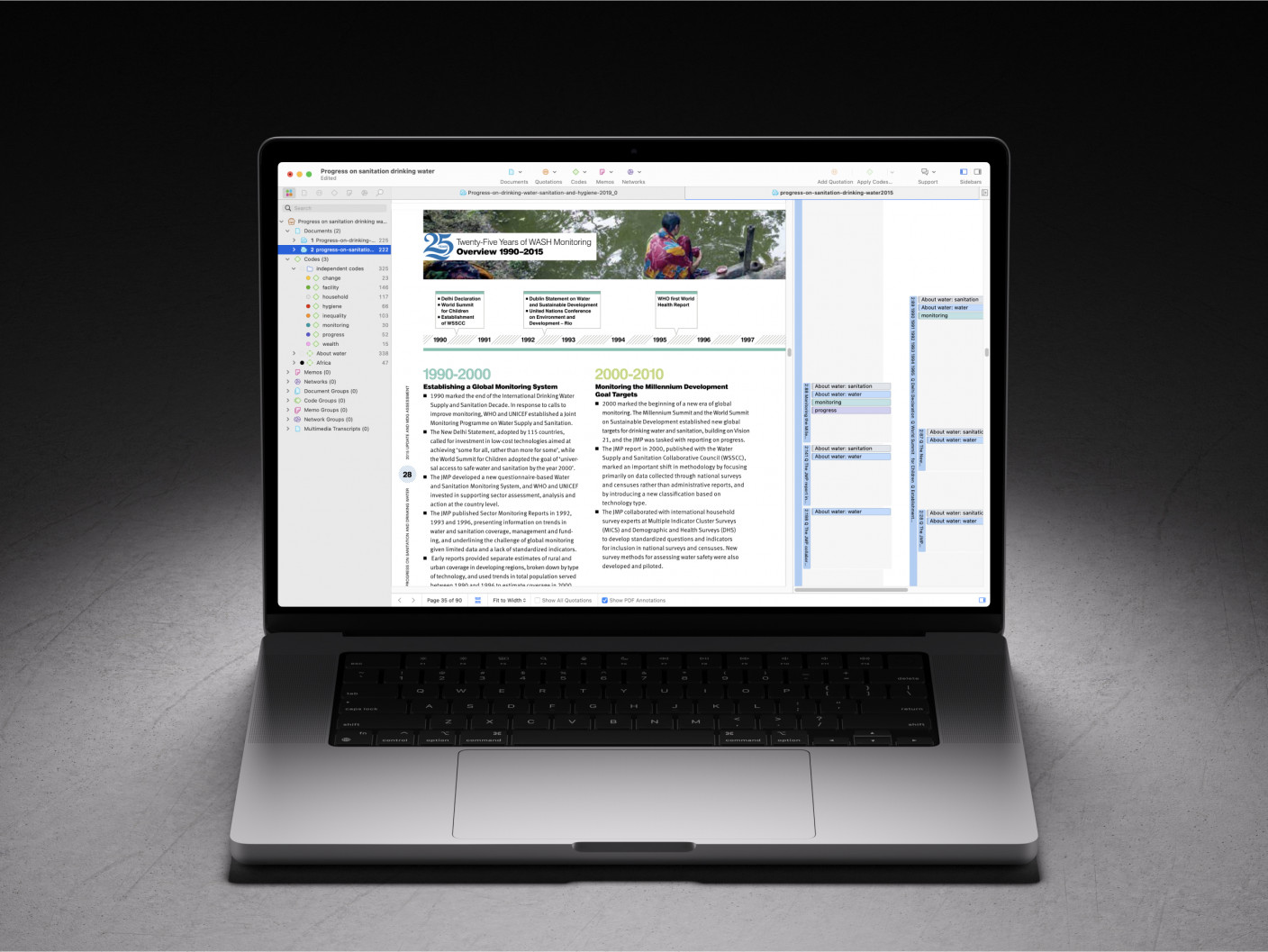
How to perform document analysis
Performing document analysis is a structured process that ensures researchers can derive meaningful, qualitative insights by organizing source material into structured data. Here's a brief outline of the process:
- Define the research question
- Choose relevant documents
- Prepare and organize the documents
- Begin initial review and coding
- Analyze and interpret the data
- Present findings and draw conclusions
The process in detail
Before diving into the documents, it's important to have a clear research question or objective. This serves as the foundation for the entire analysis and guides the selection and review of documents. A well-defined question will focus the research, ensuring that the document analysis is targeted and relevant.
The next step is to identify and select documents that align with the research question. Ensure that these documents are credible, reliable, and pertinent to the research inquiry. The chosen materials can vary from official reports, personal diaries, to digital resources like social media data, depending on the nature of the research.
Once the documents are selected, they need to be organized in a manner that facilitates smooth analysis. This could mean categorizing documents by themes, chronology, or source types. Digital tools and data analysis software, such as ATLAS.ti, can assist in this phase, making the organization more efficient and helping researchers locate specific data when needed.

With everything in place, the researcher starts an initial review of the documents. During this phase, the emphasis is on identifying patterns, themes, or specific information relevant to the research question.
Coding involves assigning labels or tags to sections of the text to categorize the information. This step is iterative, and codes can be refined as the researcher looks deeper at the data.
After coding, interesting patterns across codes can be analyzed. Here, researchers seek to draw meaningful connections between codes, identify overarching themes, and interpret the data in the context of the research question.
This is where the hidden insights and deeper understanding emerge, as researchers juxtapose various pieces of information and infer meaning from them.
Finally, after the intensive process of document analysis, the researcher consolidates their findings, crafting a narrative or report that presents the results. This might also involve visual representations like charts or graphs, especially when demonstrating patterns or trends.
Drawing conclusions involves synthesizing the insights gained from the analysis and offering answers or perspectives in relation to the original research question.
Ultimately, document analysis is a meticulous and iterative procedure. But with a clear plan and systematic approach, it becomes a potent tool in the researcher's arsenal, allowing them to uncover profound insights from textual data.

What is text analysis?
Text analysis, often referenced alongside document analysis, is a method that focuses on extracting meaningful information from textual data. While document analysis revolves around reviewing and interpreting data from various sources, text analysis hones in on the intricate details within these documents, enabling a deeper understanding. Both these methods are instrumental in fields such as linguistics, literature, social sciences, and business analytics.
In the context of document analysis, text analysis emerges as a nuanced exploration of the textual content. After documents have been sourced, be it from books, articles, social networks, or any other medium, they undergo a preprocessing phase. Here, irrelevant information is eliminated, errors are rectified, and the text may be translated or converted to ensure uniformity.
This cleaned text is then tokenized into smaller units like words or phrases, facilitating a granular review. Techniques specific to text analysis, such as topic modeling to determine discussed subjects or pattern recognition to identify trends, are applied.
The derived insights can be visualized using tools like graphs or charts, offering a clearer understanding of the content's depth. Interpretation follows, allowing researchers to draw actionable insights or theoretical conclusions based on both the broader document context and the specific text analysis.
Merging text analysis with document analysis presents unique challenges. With the proliferation of digital content, managing vast data sets becomes a significant hurdle. The inherent variability of language, laden with cultural nuances, idioms, and sometimes sarcasm, can make precise interpretation elusive.
ATLAS.ti as text analysis software
Many text analysis tools exist that can facilitate the analytical process. ATLAS.ti offers a well-rounded, useful solution as a text analytics software. In this section, we'll highlight some of the tools that can help you conduct document analysis.
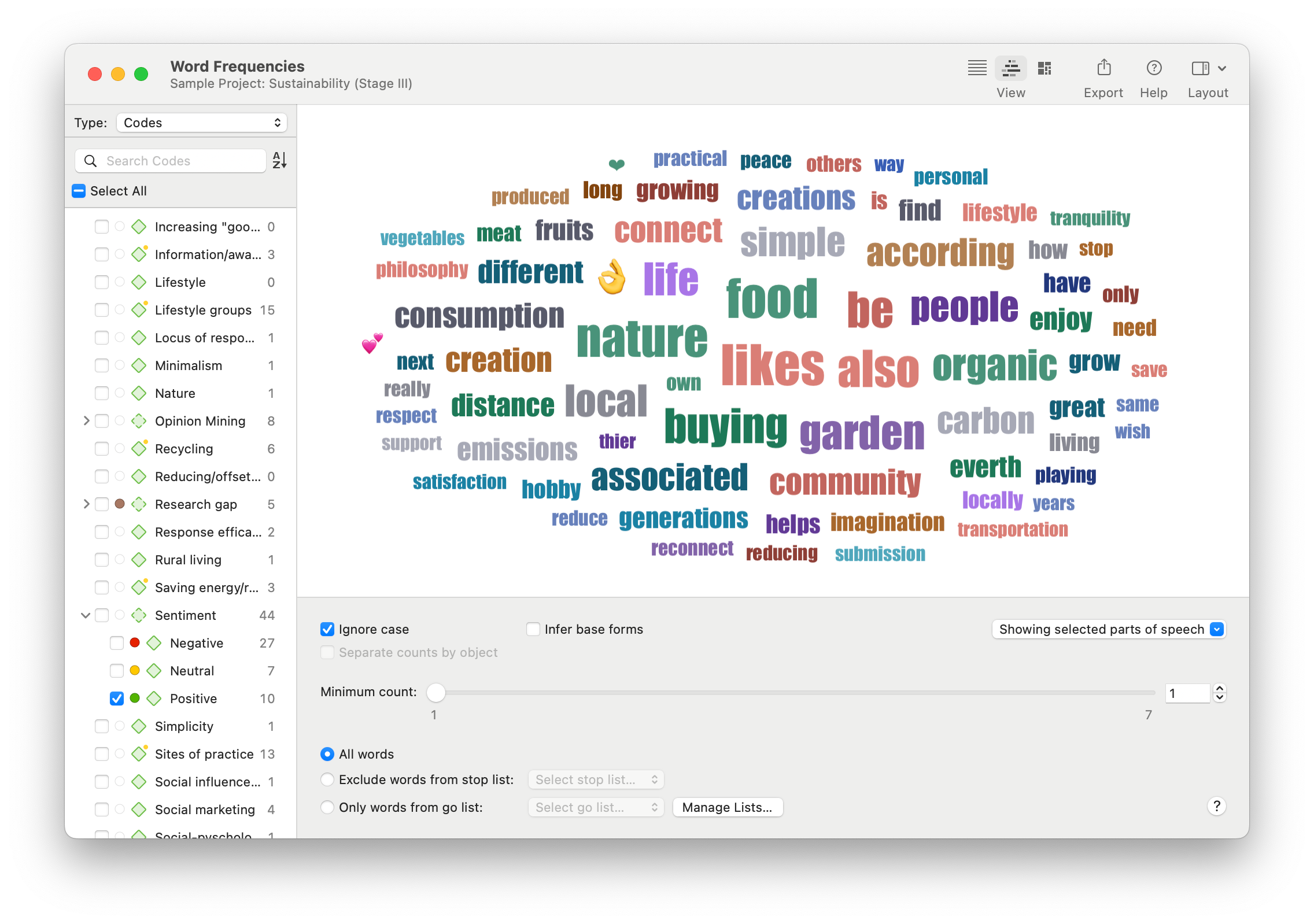
Word Frequencies
A word cloud can be a powerful text analytics tool to understand the nature of human language as it pertains to a particular context. Researchers can perform text mining on their unstructured text data to get a sense of what is being discussed. The Word Frequencies tool can also parse out specific parts of speech, facilitating more granular text extraction.
Sentiment Analysis
The Sentiment Analysis tool employs natural language processing (NLP) and machine learning to analyze text based on sentiment and facilitate natural language understanding. This is important for tasks such as, for example, analyzing customer reviews and assessing customer satisfaction, because you can quickly categorize large numbers of customer data records by their positive or negative sentiment.
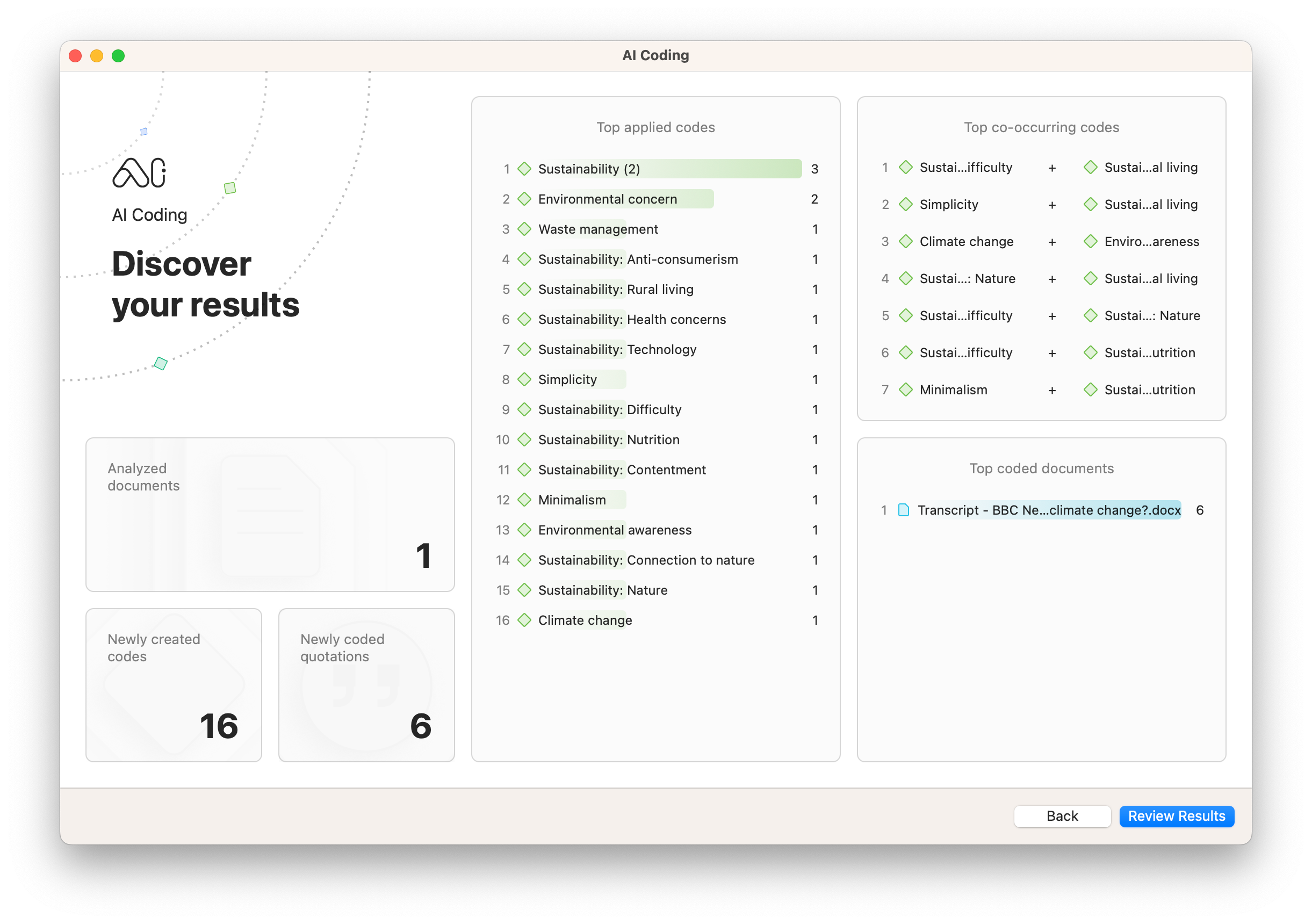
AI Coding
AI Coding relies on massive amounts of training data to interpret text and automatically code large amounts of qualitative data. Rather than read each and every document line by line, you can turn to AI Coding to process your data and devote time to the more essential tasks of analysis such as critical reflection and interpretation.
These text analytics tools can be a powerful complement to research. When you're conducting document analysis to understand the meaning of text, AI Coding can help with providing a code structure or organization of data that helps to identify deeper insights.
AI Summaries
Dealing with large numbers of discrete documents can be a daunting task if done manually, especially if each document in your data set is lengthy and complicated. Simplifying the meaning of documents down to their essential insights can help researchers identify patterns in the data.
AI Summaries fills this role by using natural language processing algorithms to simplify data to its salient points. Text generated by AI Summaries are stored in memos attached to documents to illustrate pathways to coding and analysis or to highlight how the data conveys meaning.

