


- Handling qualitative data
- Transcripts
- Field notes
- Memos
- Survey data and responses
- Visual and audio data
- Data organization
- Data coding
- Coding frame
- Auto and smart coding
- Organizing codes
- Qualitative data analysis
- Content analysis
- Thematic analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- Inductive reasoning
- Inductive vs. deductive reasoning
- Qualitative data interpretation
- Qualitative data analysis software
- How to cite "The Ultimate Guide to Qualitative Research - Part 2"
- Thematic analysis vs. content analysis
Content analysis
Qualitative data collection usually leads to a strictly qualitative data analysis, but that need not always be the case. If a required analysis involves quantifying data, there are a number of data organization and data analysis methods that might be helpful in giving structure to raw data for frequency or statistical analysis.

This part of the guide will explore the idea of quantitative content analysis. Where quantitative analysis is useful, there are tools in qualitative data analysis software like ATLAS.ti that can reorganize your data for a content analysis that can supplement your use of qualitative research methods. Let's explore content analysis by providing a brief overview of this approach, then by looking at the quantitative aspects of content analysis.
What is meant by content analysis?
Content analysis, in its simplest form, is a research method for interpreting and quantifying textual data, such as speeches, interviews, articles, social media posts, and so on. It allows researchers to sift through large volumes of data to identify patterns, themes, or biases and turn these into quantifiable variables that can be further analyzed.
At its core, content analysis combines elements of both qualitative and quantitative research methods. The method itself is systematic and replicable, aiming to condense a significant amount of text into fewer content categories based on explicit rules of coding. Yet, the interpretive component of understanding the context, nuances, and underlying meanings of the content being analyzed remains essential, borrowing heavily from qualitative research traditions.
This flexibility makes content analysis a versatile research approach applicable to numerous disciplines, such as communication, marketing, sociology, psychology, and political science, among others. Its uses range from studying cultural shifts over time, media representation of specific groups, political speeches, sentiments expressed in social media, and much more.
Differences from other research methods
The uniqueness of content analysis primarily stems from its ability to convert qualitative textual data into quantitative data, which can then be systematically examined. This capability sets it apart from many other research methodologies, each of which has its strengths and weaknesses.
Content analysis offers a less intrusive way of understanding a subject matter or phenomenon than more interpretive approaches. Unlike with an ethnographic or observational approach, there's no direct involvement with the study's subjects. Instead, the researcher examines texts and communications to uncover patterns, themes, or biases. This can be especially advantageous when researching sensitive topics or populations that are difficult to access.
Contrasting with quantitative methods associated with surveys and experiments, content analysis allows for a more contextual and nuanced understanding of data. While surveys and experiments can yield numerical data about attitudes, behaviors, and opinions, they often lack depth and fail to capture the richness of subjective experiences. Content analysis, on the other hand, provides more depth by enabling the researcher to study the intricacies of language and communication.
In comparison to discourse analysis, another method for studying a text, content analysis is more focused on the manifest content - the actual text - rather than the underlying discourses or power dynamics. Discourse analysis typically explores the relationships between text, context, and societal structures.
Lastly, unlike thematic analysis, which identifies, analyzes, and reports themes within data, content analysis goes a step further by transforming these themes into measurable variables. This quantification allows researchers to perform statistical analyses, giving content analysis an edge in examining the relationships between variables.
In essence, content analysis straddles the line between qualitative and quantitative methodologies, extracting the best of both worlds. It allows researchers to maintain the depth and richness of qualitative data while taking advantage of the numerical robustness of quantitative analysis. This makes content analysis a valuable addition to the researcher's toolkit.
Advantages of content analysis
Content analysis offers several advantages that make it a valuable tool for researchers in various disciplines. These advantages extend across its methodological flexibility, analytical depth, and practical adaptability.
- Methodological flexibility: Content analysis allows for both qualitative and quantitative research, enabling researchers to explore themes in-depth while also making quantifiable comparisons. It's a versatile method, adaptable to a variety of research questions and data sources.
- Rich, in-depth analysis: Content analysis provides a rich, textured understanding of data. Coding and categorizing allow researchers to delve into the complexities of language and communication, exploring nuanced meanings and connotations.
- Unobtrusive method: As content analysis involves studying existing texts and communications, it is an unobtrusive method that does not require interaction with research participants. This can make it an excellent choice for sensitive research topics.
- Ability to handle large data sets: Content analysis can manage large volumes of textual data, making it suitable for studies involving extensive texts or long timeframes. As we will see later in this section, the coding process in a content analysis approach can thus be relatively more straightforward.
- Replicability: The systematic nature of content analysis lends itself to replicability. By creating explicit rules for coding and categorizing, other researchers can reproduce the study, enhancing its reliability.
- Longitudinal analysis: Content analysis allows for longitudinal studies, as it can examine texts and communication over extended periods. This ability can be invaluable for tracking changes and trends over time.
- Cost-effective: Compared to many other research methods, content analysis can be a cost-effective approach. Since it primarily involves analyzing existing texts, it often requires fewer resources than methods involving primary data collection.
The flexibility, depth, and practicality of content analysis make it a powerful tool for answering a range of research questions. Despite some limitations, which we will explore in the next section, the advantages of content analysis often make it an appealing choice for researchers.
Disadvantages of content analysis
While content analysis is a valuable tool, it's essential to acknowledge its limitations. These include:
- Dependence on the quality of source materials: Content analysis relies on the quality of the source materials. If the documents or texts used for analysis are biased, incomplete, or inaccurate, it can lead to skewed results.
- Contextual understanding: Texts often derive their meaning from context. Isolating texts for analysis can sometimes result in the loss of essential contextual information, which may affect the overall interpretation of the results.
- Coding and categorization limitations: The process of coding and categorizing can be time-consuming and prone to bias or error, potentially affecting the reliability and validity of the results.
- Lack of depth compared to other qualitative methods: While content analysis allows for in-depth analysis, it may not reach the same level of depth as methods such as interviews or participant observations, particularly when exploring participants' feelings, thoughts, or motivations.
- Difficulty in establishing causality: Content analysis can identify patterns and associations in the data but establishing causality can be challenging due to its primarily descriptive nature. As a result, conducting conceptual and relational analysis can prove challenging.
- Focus on manifest content: Content analysis typically focuses on manifest content - the visible, surface content. Latent content, which refers to the underlying meanings or connotations, can sometimes be overlooked, limiting the depth of analysis.
Despite these limitations, with careful consideration and thoughtful application, content analysis remains a useful method. Understanding its potential drawbacks helps researchers apply the method more effectively and interpret their findings with due consideration. The next section will introduce qualitative content analysis, a specific type of content analysis that, while sharing some of the limitations mentioned here, offers unique advantages of its own.
What is qualitative content analysis?
Qualitative content analysis is a specific type of content analysis that primarily focuses on the interpretation and understanding of textual data. While it shares some similarities with its quantitative counterpart—such as the use of systematic and replicable methods—qualitative content analysis tends to dive deeper into the nuances, meanings, and contexts of the data.
At the heart of a qualitative analysis is the process of categorizing and coding data to identify patterns, themes, and relationships. The categories are usually derived inductively—that is, they emerge from the data itself rather than being pre-established. This approach offers a higher degree of flexibility and is especially beneficial when exploring a new or under-researched area.
An excellent example of the application of qualitative content analysis can be seen in qualitative health research. Consider a study examining patients' experiences with a chronic disease, such as diabetes. Here, qualitative content analysis would not only identify and categorize themes related to the disease experience, such as challenges in managing the condition, the impact on daily life, or interactions with healthcare professionals. It could also delve into the patients' psychological or emotional state regarding the management of their condition, as well as their attitudinal and behavioral responses to their condition and the healthcare system. For instance, the analysis might uncover feelings of frustration or resignation, proactive strategies for disease management, or attitudes toward healthcare advice.
Another distinctive characteristic of qualitative content analysis is its emphasis on context. Rather than viewing data in isolation, it considers the broader context in which the communication occurs. It takes into account aspects like the social, cultural, and historical background, the intention of the speaker, and the perception of the audience. This contextual understanding provides a richer, more nuanced analysis.
Also noteworthy is the iterative nature of qualitative content analysis. The process of coding, categorizing, and interpreting the data is not linear but recursive. As the analysis progresses, the researcher may revise the coding scheme, refine categories, and re-interpret the data, gradually enhancing the depth and precision of the analysis.
While qualitative content analysis provides an in-depth understanding of textual data, it can be more time-consuming and require more interpretative skill than quantitative content analysis. However, as we will explore in the next sections, both methods have their unique strengths and can complement each other in providing a comprehensive understanding of the data.
Quantitative content analysis
Having explored content analysis in its broad scope and delved into qualitative analysis methods behind content analysis, we now shift our focus to quantitative content analysis. This approach retains the systematic, objective nature of content analysis but introduces a more numerical, count-based method of analyzing textual data. As such, it stands at the intersection of qualitative and quantitative research paradigms, offering the opportunity to transform the same data used in a qualitative analysis into a form that can be statistically analyzed.
In the subsequent subsections, we will define this research technique, detail the steps involved in its implementation, discuss its benefits and limitations, and illustrate its practical application with some examples. By the end of this section, you should have a solid understanding of quantitative content analysis and its role in your research toolkit.
Defining quantitative content analysis
This research approach, also known as deductive or 'classical' content analysis, is used to quantify patterns in textual data. This approach systematically transforms a text into numerical data, allowing for statistical analysis. This means that the content is categorized and counted to provide an objective, quantifiable overview of its characteristics.
Quantitative content analysis is predominantly concerned with manifest content—the visible, obvious components of the text. It examines what the text explicitly says rather than delving into possible latent meanings or underlying connotations. The text's elements—such as words, phrases, sentences, or specific themes—are coded into predefined categories, and the frequency of these categories is then quantified. This quantification allows for a more precise and broad-scale analysis of the data.
It's important to note that while quantification is a fundamental aspect of this approach, quantitative analysis still involves an element of interpretation. For instance, the development of coding schemes and the categorization of data require the researcher to understand and interpret the content. As such, even though it's labeled as 'quantitative,' this approach is still qualitative in nature.
Despite this, the predominant focus of a quantitative approach is on the numerical, allowing it to provide a structured, replicable, and count-based exploration of textual data. The value of this approach lies in its ability to deliver an empirical, data-driven understanding of the content, enabling researchers to make statistical inferences and comparisons. In the next subsection, we will discuss the steps involved in conducting quantitative content analysis.
Steps in conducting quantitative analysis
The process typically involves several key steps:
- Define the research question: The research question should be suitable for a quantitative approach. It should examine the frequency or patterns of certain aspects in a body of text.
- Select the sample: Based on the research question, decide what texts to analyze. The texts could be anything from newspaper articles, social media posts, and speeches to transcripts of interviews or focus groups. Make sure to define a clear and replicable strategy for sample selection.
- Define categories and develop a coding scheme: This step involves identifying the aspects of the text you are interested in and developing a set of categories to classify these aspects. Each category should be clearly defined, mutually exclusive, and collectively exhaustive.
- Pilot-test the coding scheme: Before you start the actual analysis, it is advisable to pilot-test the coding scheme on a smaller subset of the sample. This helps ensure that your categories cover all relevant aspects of the content and that the coding scheme is reliable.
- Code the content: In this step, the selected content is coded according to the coding scheme. Each part of the content that corresponds to a category is counted as a 'unit.' The units could be individual words, phrases, sentences, paragraphs, or even entire documents, depending on the research question and the nature of the categories.
- Analyze and interpret the data: The coded data is then analyzed, often using statistical methods. You can calculate the frequencies of each category, compare frequencies between different parts of the text or different texts, or examine the relationships between categories. The analysis should be linked back to the research question and the wider context of the research.
- Present the findings: Finally, the findings are reported in a clear and comprehensible manner, often using tables or graphs to display the frequencies of categories. It's also important to discuss the findings in the context of the research question and existing literature.
These steps provide a general framework for conducting quantitative content analysis. However, depending on the specifics of your research project, you may need to adapt or expand on these steps. For instance, if your research involves a large volume of text or multiple coders, you may need to include additional steps to ensure the consistency and reliability of the coding process.
Practical examples of quantitative content analysis
With the process outlined above, here are a few practical examples illustrating a quantitative application of content analysis.
One common application of quantitative content analysis is in media studies. For instance, a researcher might use it to examine the representation of gender roles in a sample of popular movies. The researcher could define a set of categories reflecting different aspects of gender representation, such as the occupation, behaviors, or speech of male and female characters. By coding and quantifying these categories, the researcher could provide an empirical, data-driven analysis of gender representation in movies.
In political science, a researcher might use quantitative content analysis to analyze politicians' speeches. For example, they could examine the frequency of certain themes or keywords to gain insights into a politician's focus areas or ideological leanings. This approach allows for a systematic, objective assessment of political communication.
In health research, quantitative content analysis could be used to analyze patient reviews of healthcare providers. Categories could be developed to capture aspects like the quality of care, communication skills, waiting times, etc. By coding and quantifying these categories, the researcher could identify patterns and trends in patient satisfaction.
These examples illustrate the breadth of applications for quantitative content analysis. Whether you're exploring social issues, political discourses, customer reviews, or any other type of textual data, quantitative content analysis provides a method for systematically coding, categorizing, and quantifying your data. By offering a way to transform qualitative data into a form that can be statistically analyzed, it adds a valuable tool to your research toolkit.
Using ATLAS.ti for content analysis
ATLAS.ti is particularly useful to researchers who want to conduct content analysis from both quantitative and qualitative approaches. For research inquiries that rely more on interpretation to identify patterns and abundance in the data, then thematic analysis may be more appropriate for your study.
On the other hand, when you are relying on counting words or phrases to determine key insights, a quantitative approach to content analysis will be a useful component of your study's methodology. To facilitate your analysis, a number of tools in ATLAS.ti will provide you with the ability to conduct a quantitative inquiry.
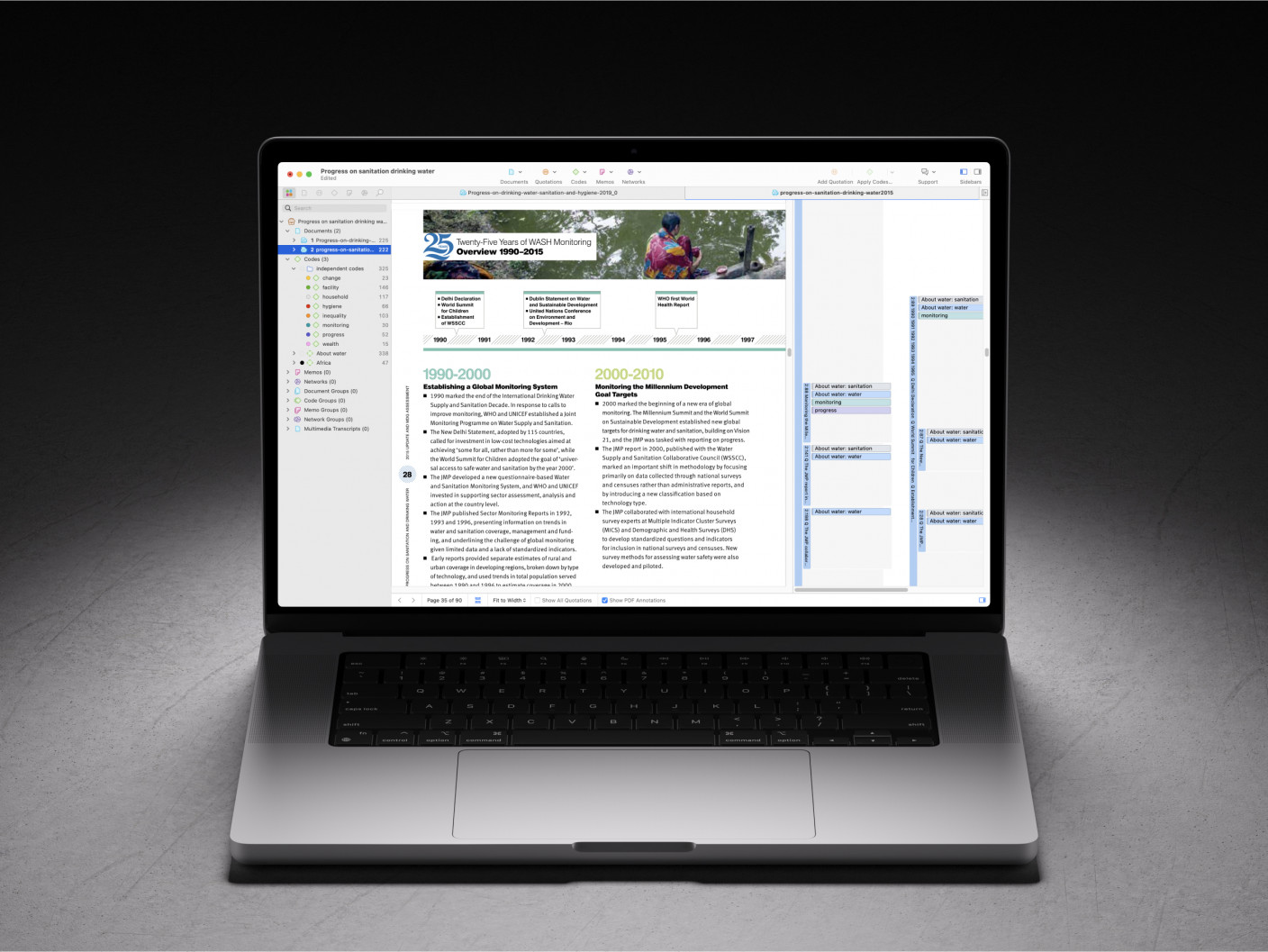
Word Frequencies and Concepts
A word cloud is a common but meaningful visualization in qualitative research, as it shows what words appear more often than others. The greater the frequency of a word, the closer to the center of the cloud that word is placed. While a word cloud relies on statistics, it presents the analysis in a visual manner that allows your research audience to quickly grasp the meaning.
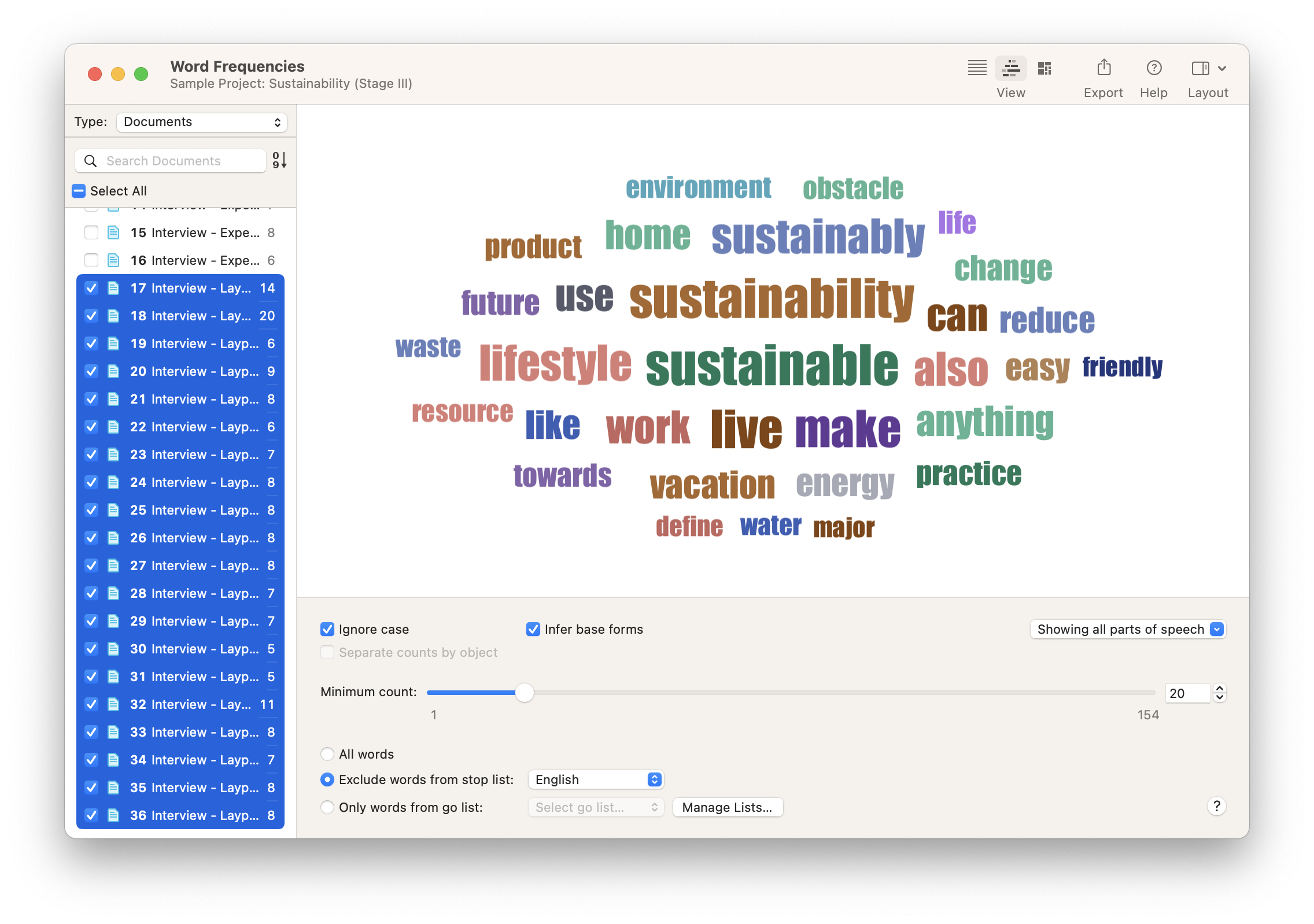
ATLAS.ti's Word Cloud tool determines the frequencies and creates the visualization quickly and easily. All the researcher needs to do is select the documents they want to analyze. They can then refine their word cloud by including or excluding certain classes of words, such as adverbs or determiners, or by setting a required minimum frequency for the word to appear in the cloud.
The Concepts tool works similarly to Word Clouds, except it relies on collocations of words to determine which phrases are more prevalent in your data than others.
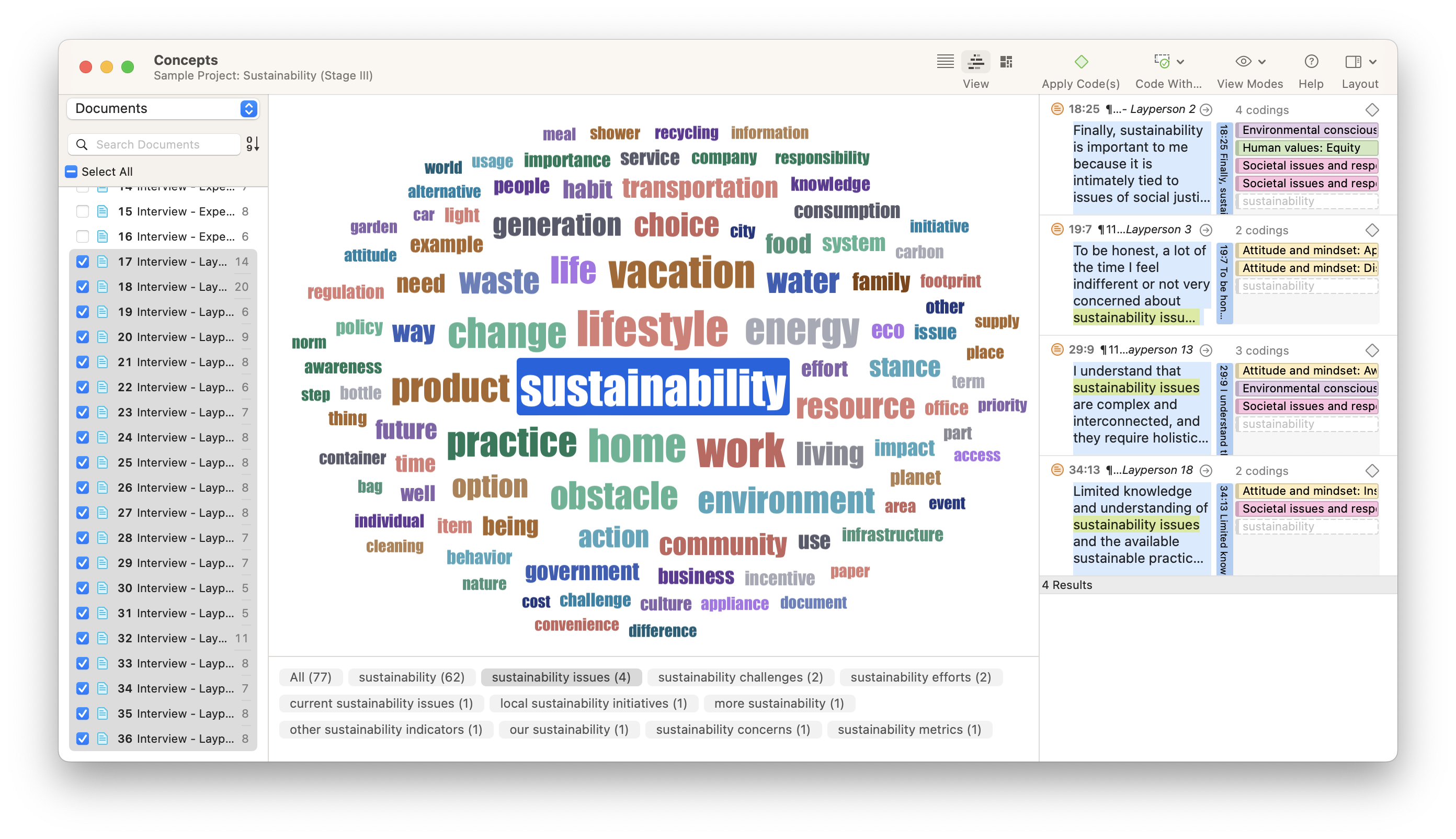
Once the researcher selects the data they want to analyze, the words included in the most common concepts will appear in a visualization resembling a word cloud. Hovering over any of these words will show which phrases are relevant to that word and where those phrases can be found in the data. This allows the researcher to look at the phrase in context and add codes as necessary.
Text Search
Most people are familiar with a text search function in a word processor or a web browser. ATLAS.ti's Text Search tool has a similar search capability but also employs language models developed through machine learning to help you expand your search quickly and efficiently.
When entering a word to search, the researcher can also choose from a list of synonyms they can include in their search. In research on sustainability, for example, the words "preserve" and "save" might be similar enough to be included in one inquiry. As a result, ATLAS.ti allows the researcher to choose related words relevant to their search.
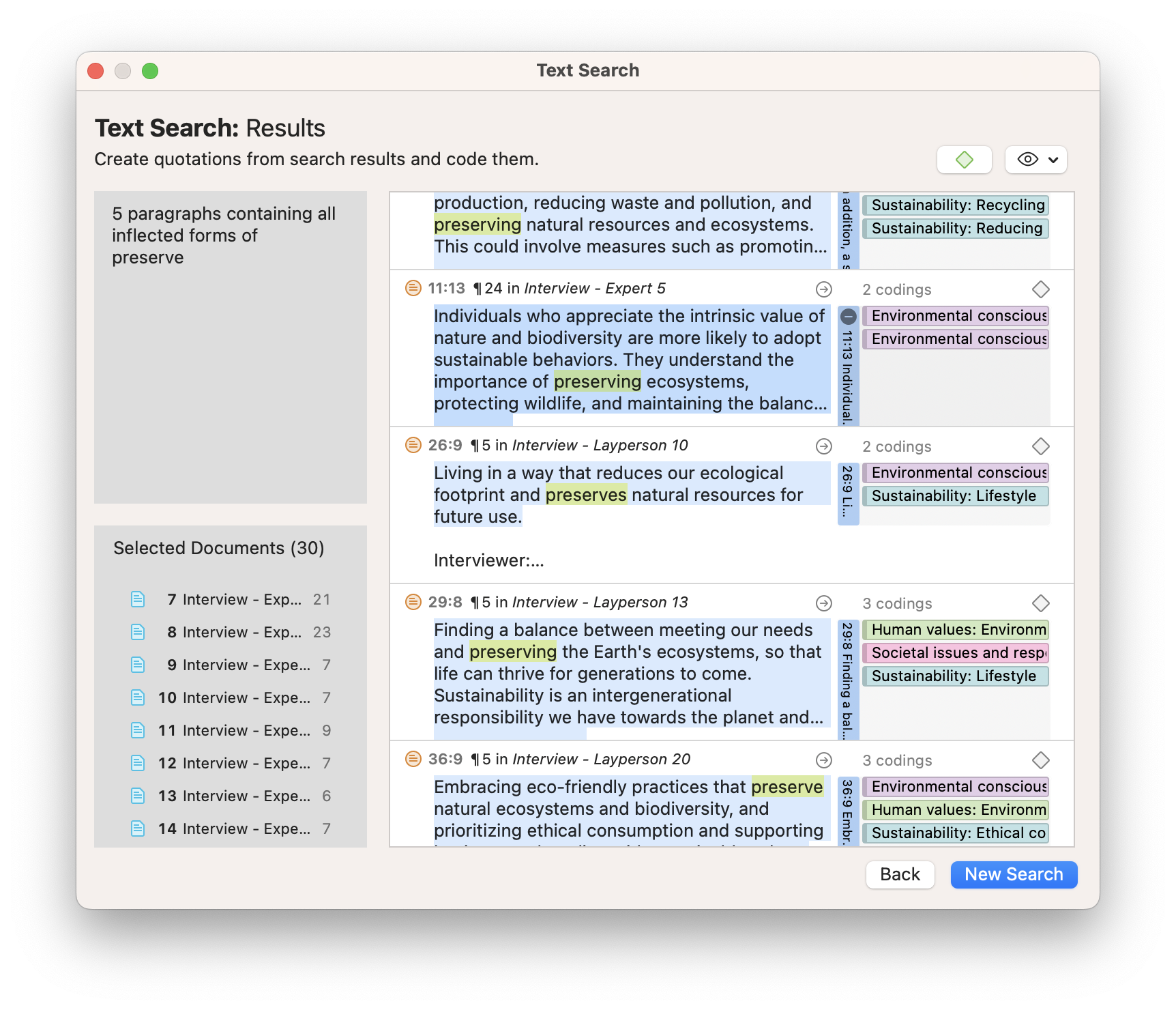
Searching for inflected forms is also important to a quantitative approach to content analysis. Given that "preserves," "preserving," and "preservation" all come from the word "preserve," it's only appropriate to include them in one search. The option in ATLAS.ti to search for inflected forms makes it easy to search the data for all possible versions of a word. And in Text Search, all results can be easily coded so those codes can be used in content analysis.