


- Handling qualitative data
- Transcripts
- Field notes
- Memos
- Survey data and responses
- Visual and audio data
- Data organization
- Data coding
- Coding frame
- Auto and smart coding
- Organizing codes
- Qualitative data analysis
- Content analysis
- Thematic analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- Inductive reasoning
- Inductive vs. deductive reasoning
- Qualitative data interpretation
- Qualitative data analysis software
- How to cite "The Ultimate Guide to Qualitative Research - Part 2"
- Thematic analysis vs. content analysis
Organizing codes: Make the best of codes for research
Coding is more than simply applying labels to data. Once you have completed the first round of coding, the next task is to organize your codes in a way that allows for efficient qualitative data analysis. Whether you are following inductive or deductive analytic approaches, organizing the list of codes will allow you to make sense of your data. In any case, researchers benefit from a disciplined approach to coding, from the initial stages of coding to the analysis of patterns in your data.

What makes a good coding system?
Codes represent the broader meaning of selected segments in your data. The goal is to condense the data into a form that is easier to analyze. Given the unstructured nature of qualitative data, qualitative researchers have extensively discussed the methodology of coding, and over the years, a consensus regarding useful practices for coding has emerged.
Steps for coding qualitative data
As there are many types of coding in qualitative research, determining which strategy is best for assigning codes to your data depends on your research inquiry. If you simply do not know where to begin in making sense of your data, you can employ descriptive coding or inductive coding. Create codes based on what meaning you glean as you read the data in-depth. In this case, you are developing the coding system as you process and organize the data.
On the other hand, if you have preconceived ideas based on existing theory about what to assess in your data, then you can implement deductive coding. Whereas an inductive code arises exclusively from the data, a deductive code comes from pre-existing concepts developed in established theory. Both inductive and deductive coding strategies can be applied to allow an exploratory analysis that can evolve flexibly and build on existing theory.
If you are engaged in research like dialogic analysis or narrative analysis, then you might be less focused on the meaning of the data and more concerned with how the data is formed. Consider how a recipe is often broken down into different parts or that a story follows a process from setting to conflict to resolution. In that case, structural coding allows you to identify the discrete parts of textual data to understand common patterns in a genre or practice.
How do you add codes to ATLAS.ti?
Whatever the research inquiry, ATLAS.ti can be used to code qualitative data. If you already have a predefined list of codes that you created from existing theory, you can add these codes into ATLAS.ti by creating codes in the Code Manager or by importing your codebook from Excel. On the other hand, if you want to inductively create codes based on your data, you can simply click on the coding button or keyboard shortcut while reading through your data and create or add codes easily.
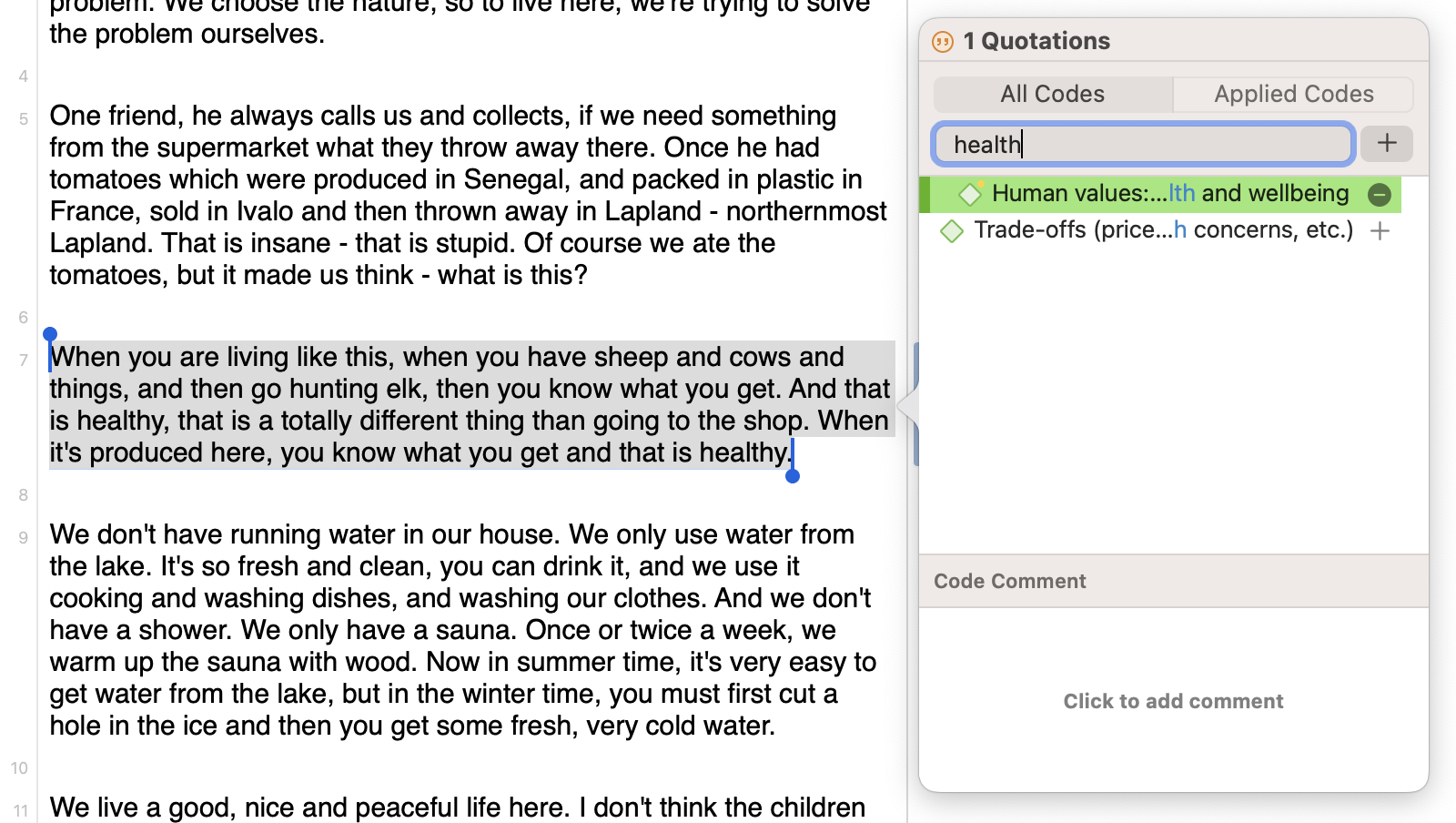
While coding is an important skill in qualitative research methodology, we also acknowledge the challenges of coding large sets of data by hand. As a result, auto-coding tools in ATLAS.ti can also assist with the coding process. Tools like AI Coding and Sentiment Analysis are ideal for quickly and automatically coding data to allow researchers to analyze their data faster.
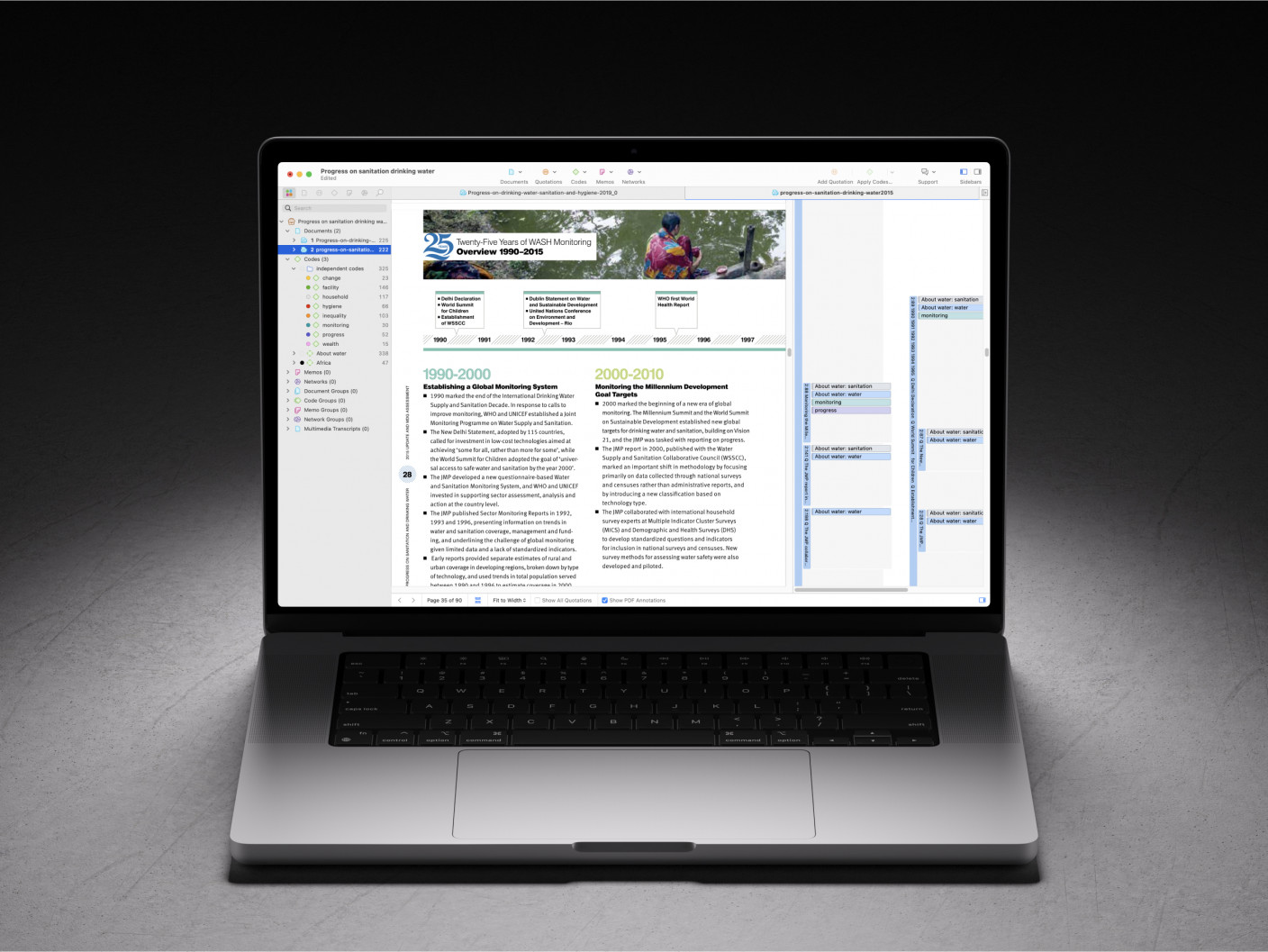
What is the Code Manager in ATLAS.ti?
The Code Manager provides you with the interface to organize and edit all your codes. You can rename, merge, and split codes; assign code colors and write operational definitions; and create categories, groups, and/or folders to neatly arrange codes for easier analysis. You can also gain an overview of your codes with different graphics and export reports, such as the codebook.
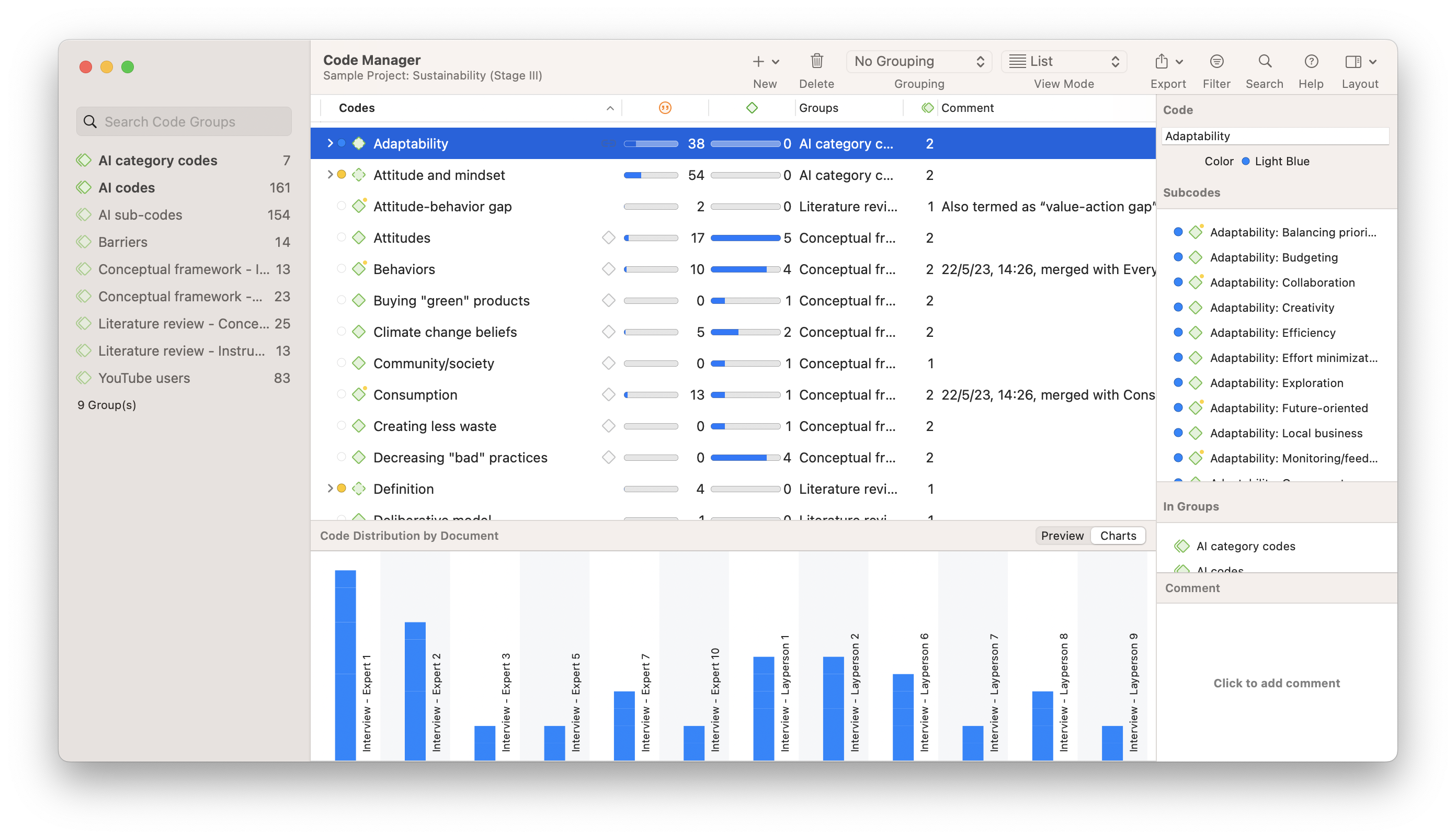
Viewing the manager of a fully coded project can also yield some important insights for data analysis. The grounded numbers in ATLAS.ti, for example, show the simple frequencies of codes as they are applied to the data. At the same time, the values corresponding to density highlight the extent to which codes are linked to each other. These numbers can provide indications of how the codes have been used and the overall theoretical development.
How do you use code groups and categories in ATLAS.ti?
Identifying prevailing themes is often a key objective of qualitative research. Several elements in ATLAS.ti, such as category codes, code colors, and code groups, can provide the necessary organization for your project to identify and parse out overarching patterns and themes. Code groups, in particular, are useful when arranging codes that may otherwise belong to different parts of your coding hierarchy. Codes can be easily grouped in the Code Manager and Code Group Manager.
In addition, codes can be hierarchically structured into categories and sub-codes. Specifying category codes and sub-codes makes it easy to conduct flexible and complex queries that can cut across categories. Analysis can also easily shift between focusing on the finer details of sub-codes and examining broader patterns among themes.
Code groups and categories can be treated as discrete units of analysis (as if each were its own code). These units can then be analyzed with tools such as Code Co-Occurrence Analysis and Code-Document Analysis to build rich and nuanced insights.
From the coding process to data analysis
As tedious as coding might sound, it is a necessary step in providing the specific structure that analysis requires. It is from this structure that the researcher makes sense of the data.
Of course, coding is a deeply involving process. As a result, ATLAS.ti provides numerous tools and features that make the coding process easier and more comfortable.