
How research AI can enhance your analysis

- How research AI can enhance your analysis
- Data analysis
- Challenges in data analysis
- Artificial intelligence
- AI in research
- ATLAS.ti's AI tools
- Applications for ATLAS.ti's AI tools
How research AI can enhance your analysis
Artificial intelligence (AI) and machine learning can identify essential data points in your research to inform and generate critical insights. Learn about how AI tools in ATLAS.ti can work for you.
Overview
Organizing raw data and preparing it for data analysis are arduous, time-consuming tasks, especially when you're dealing with large sets of data. Thankfully, researchers and data analysts can benefit from artificial intelligence and machine learning to facilitate coding and data analysis. AI and machine learning technology make finding actionable insights faster and easier than ever before.
Let's look at artificial intelligence, its applications for qualitative research, and how ATLAS.ti gives you access to powerful tools that can help you automate coding and predict outcomes arising from the data in your research project. Before that, however, we will need to have a fuller understanding of data analysis to gain a sense of artificial intelligence's role in the research process.
- Data analysis
- Objectives for data analysis
- Challenges in data analysis
- Artificial intelligence
- AI in research
- ATLAS.ti's AI tools
- Applications for ATLAS.ti's AI tools
- AI and human input

Data analysis
The central goal of any research is to organize information that is otherwise unstructured and whose understanding can benefit from greater systematization. Without organization through data analysis, information cannot be easily understood or synthesized to create new knowledge.
The periodic table of elements is a well-known example of this systematization of knowledge, where elements like hydrogen and mercury are distinguished by aspects such as atomic number and atomic weight. Novices who lack a systematic understanding of the discrete aspects defining an element thus find it challenging to understand differences between elements.
Data analysis or data analytics aids researchers and data scientists in organizing knowledge in a more systematic and ordered manner. By turning raw data into ordered concepts, a researcher analyzes data to more easily make predictions based on the information.
To take business analytics as an example, suppose one objective is to increase sales by identifying aspects of customer satisfaction in mobile platforms. A question like "Are you happy with our program?" is too simplistic and may not provide the most detailed answers a company is looking for to improve their products.
Deeper research on this topic might involve interviewing business users to see what factors inform their purchasing and evaluation decisions. A thorough text analysis of interview transcripts can help generate a concept of customer satisfaction with aspects like this:
- cost of software
- performance of software
- capabilities of software
- ease of use
Having ordered the information gathered from research in these and other commonly found aspects associated with customer satisfaction, the business can ask customers more specific and helpful questions:
- How much would you pay for a perpetual license for this software?
- How much time have you saved using this software?
- What business processes have been made easier with this software?
- How user-friendly is this software?
The insights gained from answers to these questions can help to generate and order further concepts such as the nature of user-friendliness and cost performance.
Data analytics
Whereas data analysis gives researchers and data analysts more information, advanced data analytics looks for actionable insights that can lead to making critical decisions relevant to a research inquiry. For example, the answers to the above questions about cost and time can inform the decision-making process regarding future program developments. More efficient processes in new developments aimed at making the product faster might help to justify a higher cost to the end-user. Determining the extent to which the program can be made faster to command a more expensive price is an objective of data analytics.
Business researchers can utilize ATLAS.ti as an analytics platform to identify market trends, customer behavior, and product preferences. ATLAS.ti provides various tools for text analysis and text classification to allow researchers to perform analytics that can help guide decision-making.
Challenges in data analysis
The task of making data-driven decisions in research typically follows this process:
- utilizing different data sources to collect sufficient amounts of data
- organizing data so that it is easier to quickly understand
- conducting data analysis to identify patterns for valuable insights
AI and machine learning can assist researchers with the data organization and data analysis, particularly when data collection yields great amounts of data in various forms. Essentially, the need for AI analytics arises from the advent of big data, where faster and more automated data collection poses greater demands on the time and effort of researchers to analyze incredible amounts of insufficiently organized information.
The complexity of all types of meaningful data analysis can be formidable especially as the size and scope of research expand. The task of analyzing vast amounts of data can be time-consuming and challenging to complete in a reliable and transparent way.

Imagine that a business data analyst has conducted an interview study that has collected hundreds of pages of transcripts. Traditional data analytics might involve reading through every single page of this data set and manually summarizing the data through coding to generate the necessary business intelligence to inform important decisions. This requires time and effort that, however important it is to the data analysis process, can also deplete researchers' energy and delay decision-making.
Moreover, the current prospects of big data elevate data analysis automation from a beneficial quality to an outright necessity in research applied at scale. The vast scale of big data collection makes traditional data analytics with manual processes alone are incapable of producing necessary data-driven decisions.
How can a lone researcher analyze data from large projects in a way that identifies the most powerful insights for data-driven decisions? How can this research be conducted in an efficient manner that saves time and effort without sacrificing reliability and accuracy? How can data science solve the challenges of increasingly complex data analysis? For answering questions such as these, an AI solution is required.
Artificial intelligence
The concept of AI emerged decades ago in pursuit of the idea that computers could eventually achieve the complexity and capabilities of the human brain but at speeds that surpass human effort. Data scientists have developed machine learning techniques to build an artificial intelligence that can understand data, infer meaning from that data, and mimic or extend the data it has processed.

The most well-known applications of data science include AI analytics in chess competitions, customer service contexts, and smart home devices. In each of these contexts, AI relies on predictive analytics to guide decision-making processes and efficient automation of once-manual tasks.
How AI and machine learning work
While the whole topic of AI and machine learning may sound complicated, what machine learning models ultimately do is process large amounts of data with the goal of making predictions in analyzing new data. Think about a person you know well and the patterns in the way they talk. What words do they use more often than others, and in what situations? If you need to ask them for a favor, how do you word your request to have the best chance of them agreeing to it?
The questions in this context are not much different than the processes involved in AI. When making a request of others, a person considers past experiences and interactions with them to produce a best guess of how to form the most appropriate utterance.
The task of a data scientist is very much the same. Suppose the goal is to produce AI-powered tools relevant for business intelligence. That data scientist feeds training data into machine learning to develop AI. The data is relevant to business contexts as an example that the AI is to learn from.
After incorporating natural language processing to help process this text, artificial intelligence can conduct data analytics on new text to make predictions about the insights it might contain. The machine learning aspects of AI then internalize those decisions to recursively develop intelligence. In effect, it becomes smarter as it processes more data so that its capabilities are more applicable at greater scales.
GPT
Most recently, ChatGPT has generated the most excitement for the development of artificial intelligence. ChatGPT takes advantage of natural language processing to be capable of having online conversations with people. This sort of progress in AI highlights the potential applications that artificial intelligence has for textual data.
The GPT in ChatGPT stands for Generative Pre-trained Transformer. As explained above, GPT models rely on enormous amounts of training data to learn and make predictions about language usage. The analysis from GPT models has significant implications for many different fields, but it can be especially powerful for research purposes.
AI in research
As research projects become larger, data analysts have a growing need to automate the parts of the research process that are the most repetitive and have traditionally required the most manual effort. This is especially true in the business world given the need to quickly analyze business data faster than what traditional data analytics can provide. Unlike a traditional data analytics platform, AI-powered data analytics can provide a dynamic analysis to help its users make better decisions based on their data.
As a result, qualitative data analysts have been making impressive developments in AI and machine learning to process raw data and identify critical data points that can lead to meaningful insights. Experts in data science and developers of artificial intelligence use machine learning to conduct a text analysis of vast amounts of data to generate complex models of language that can predict where useful information can be found and what sentiments they are likely to carry.
In any context involving big data, this sort of automated prediction is a necessary element to answering questions and generating actionable insights. Social science research projects of all sizes can benefit from automating some data analysis tasks. Even smaller projects primarily containing unstructured qualitative data can benefit from machine learning and AI analytics to help save time and effort.
Research uses for artificial intelligence
The implications of AI hold significant potential for the research process. In most cases in qualitative research, data analysts organized data by applying short, descriptive codes to segments of text, making it easier to summarize large sets of data. This requires the researcher to look at data, page by page, line by line, manually applying codes when they identify a possible insight. Under manual conditions, it is a time-consuming task that is still necessary to establish research rigor that other researchers need to see before considering a research project credible.
The manual data analysis process is also mentally taxing. A qualitative researcher might employ dozens, if not hundreds, of codes to represent the various data segments in their project. Keeping all of those codes - and their associated meanings - in mind can be arduous task.
Imagine that an educational researcher has a code labeled "assessment." Do they only mean to code the formal assessments like tests and essays or do they also mean informal assessments like questions to students during class? In ATLAS.ti, codes can be accompanied by comments so researchers can have a clear references to fall back on when they need more elaboration on the meaning of a particular code.
Nonetheless, both challenges highlight the limitations that a human researcher might encounter without assistance from AI-powered automation. Ultimately, the goal of AI analytics is to process enough data through machine learning to develop a reliable model for extracting essential insights from data. Meeting this objective through AI data analysis would save time in the research process and make the representations of qualitative data more credible.
Research applications of artificial intelligence
ATLAS.ti already employs AI and machine learning in analyzing all sorts of qualitative data:
- survey data
- blog comments
- interview transcripts
- text articles
- social media
Each of these data sources can produce incredible amounts of data that ATLAS.ti can analyze through artificial intelligence and machine learning. Without AI capabilities, a researcher would need to manually sift through pages and pages of unprocessed data to comb for relatively hidden insights useful to their inquiry.
Primarily, the AI analytics embedded in ATLAS.ti can either automate coding, identify essential insights, or suggest new lines of research inquiry. What this means is that, in addition to AI being able to help researchers analyze data, it can also help guide researchers on what they should research next. As we'll see in the following sections, ATLAS.ti's AI tools allow researchers to perform predictive analytics in addition to various other forms of essential analysis with all their research projects.

ATLAS.ti's AI tools
Artificial intelligence and machine learning are important aspects of data analysis in ATLAS.ti. AI-powered tools that incorporate machine learning techniques to facilitate automatic coding and advanced searching are embedded in our software to provide advanced analytics that can help you find valuable insights faster.
AI Coding
The newest artificial intelligence tool in ATLAS.ti conducts data analytics at scale to automatically suggest codes for your research project. The AI data analysis in this tool relies on GPT models developed by the cutting-edge OpenAI research laboratory.
The machine learning and natural language capabilities in OpenAI's GPT models have been tested with scientific texts, interview transcripts, and other forms of textual data representative of ATLAS.ti users' data analysis needs. Learning from these texts, OpenAI's machine learning capabilities have led to a developed AI analytics model that can look at data and propose new codes at a much faster speed than a manual data analysis is capable of.
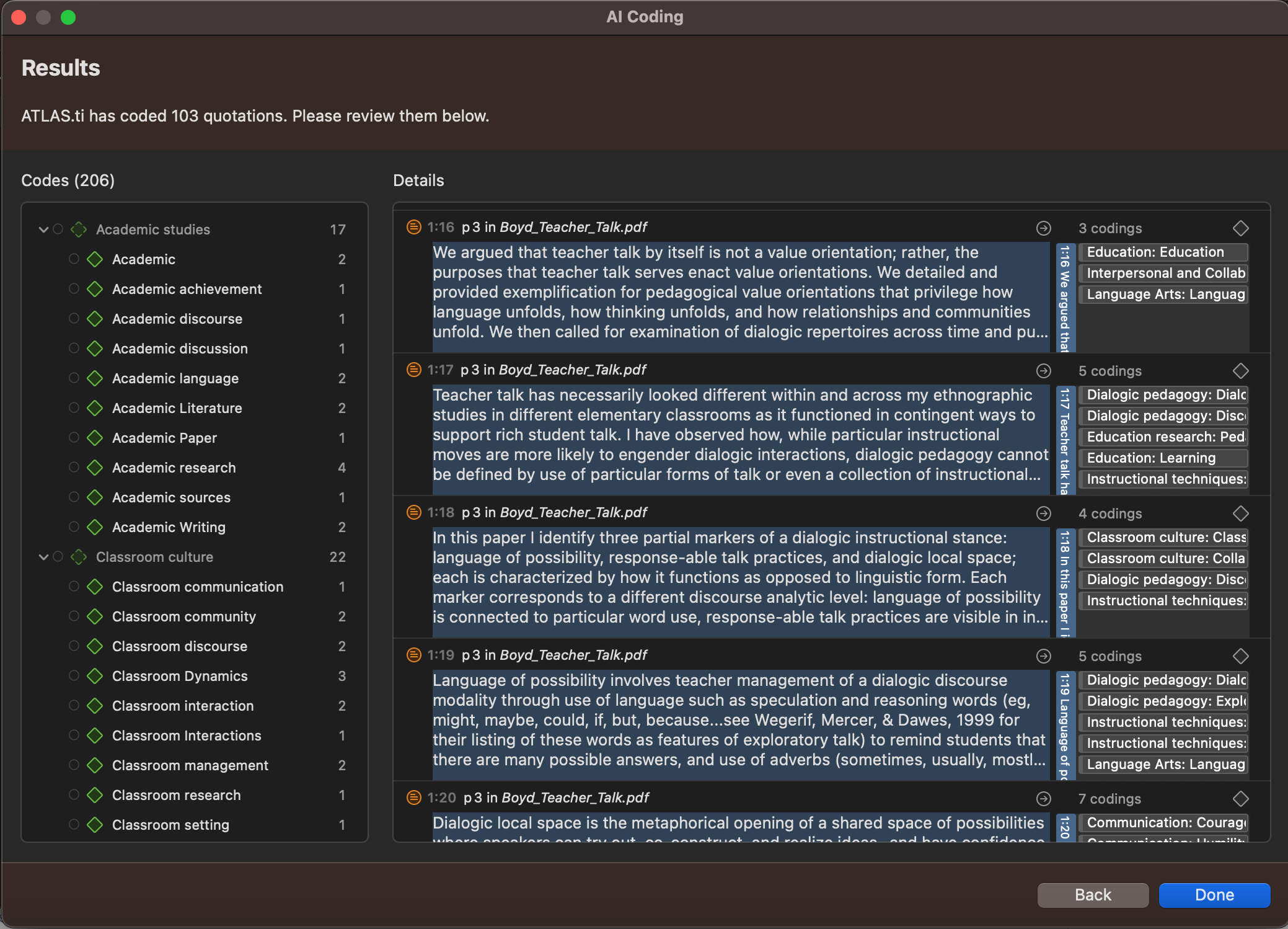
The AI Coding tool promises to be easy to apply to all text data in your project. In ATLAS.ti, all you need to do is select the documents where you would like to automate the coding process. The data is processed online through OpenAI's servers where AI analytics examine the data and make informed predictions about what codes should be applied and where. A dialogue appears with a set of codes proposed by AI analytics for you to review.
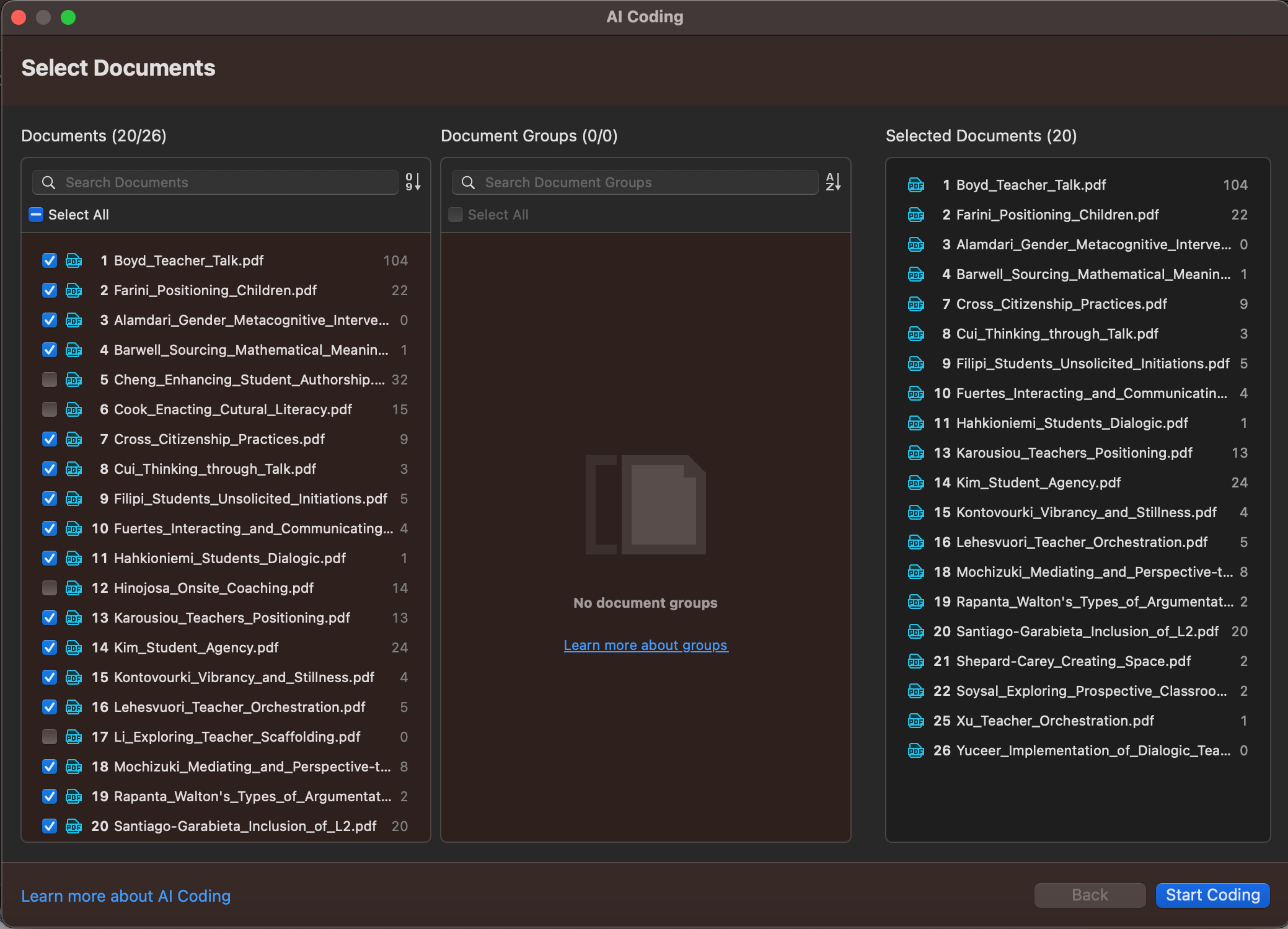
AI Coding is also visually intuitive and user-friendly. After processing data through machine learning, ATLAS.ti produces a summative visualization of results that gives data scientists advanced analytics regarding what codes can be applied to your data as well as what codes occur together. The information provided by AI analytics can illuminate the most important insights and potential inquiries that researchers can pursue next.
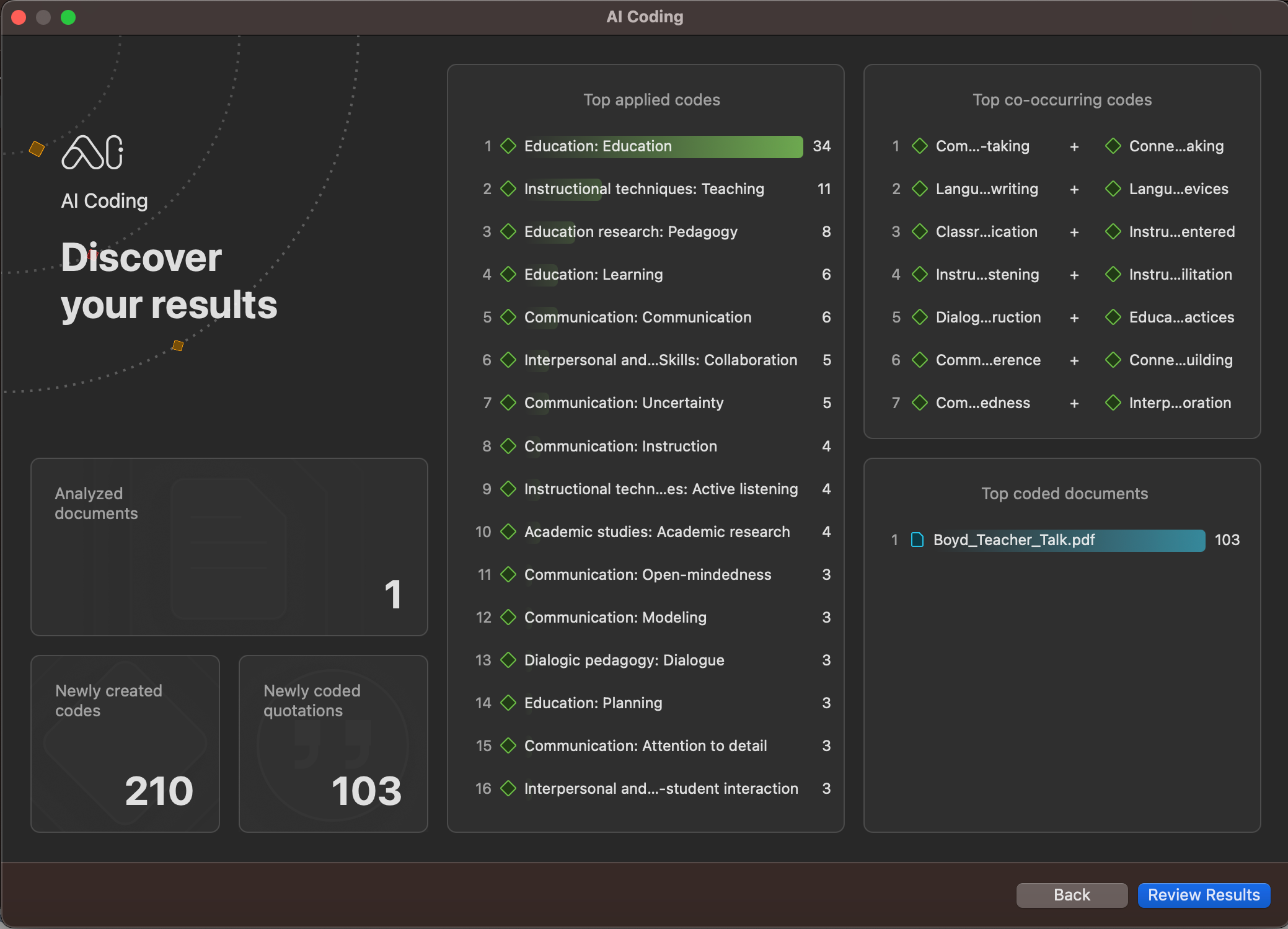
Keep in mind that the machine learning that facilitates AI Coding is cloud-based to ensure that automatic coding is determined by the most up-to-date natural language processing. This system allows you to either employ AI Coding on certain parts of your project as a guide for later coding or to simplify the entire process by coding all your data.
Text Search with AI
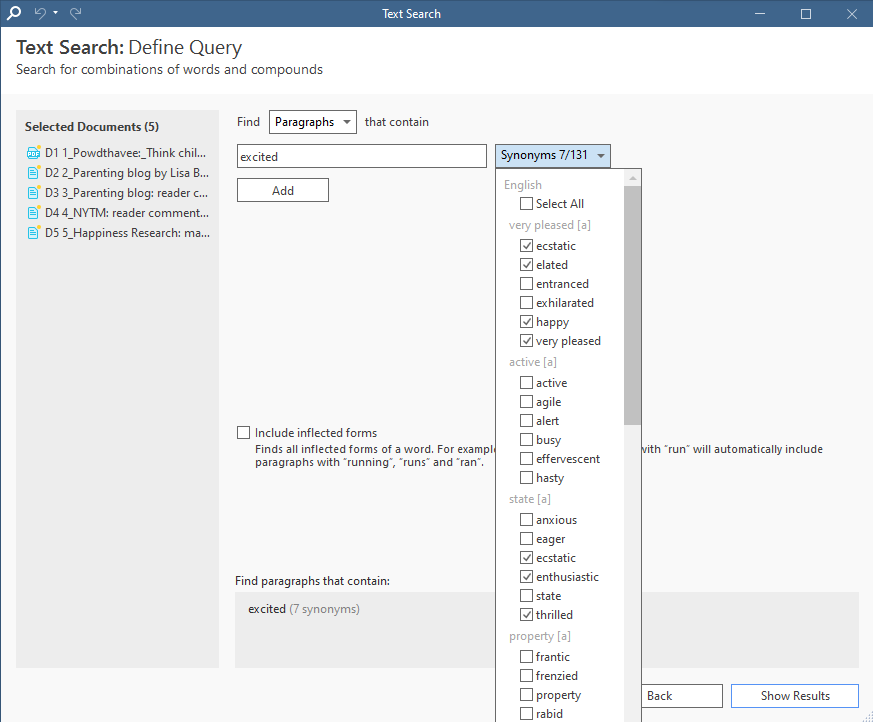
On the surface, this AI research tool looks like a simple search engine for your text documents. Using Text Search, you can input a word or phrase, and ATLAS.ti will identify paragraphs, sentences, or exact matches as potential quotations for you to apply codes. This has the capability of looking at large numbers of documents and reorganizing the most relevant data in one place, allowing for easy and efficient coding.
However, the AI aspect of Text Search lies in its ability to look for synonyms and inflected forms of a word. ATLAS.ti can suggest a list of possible synonyms that might provide the same meaning you're looking for and search for different forms of the same word (e.g., "happy" and "happiness"). The expanded search capability can help you identify more relevant segments of data quickly and with less effort.
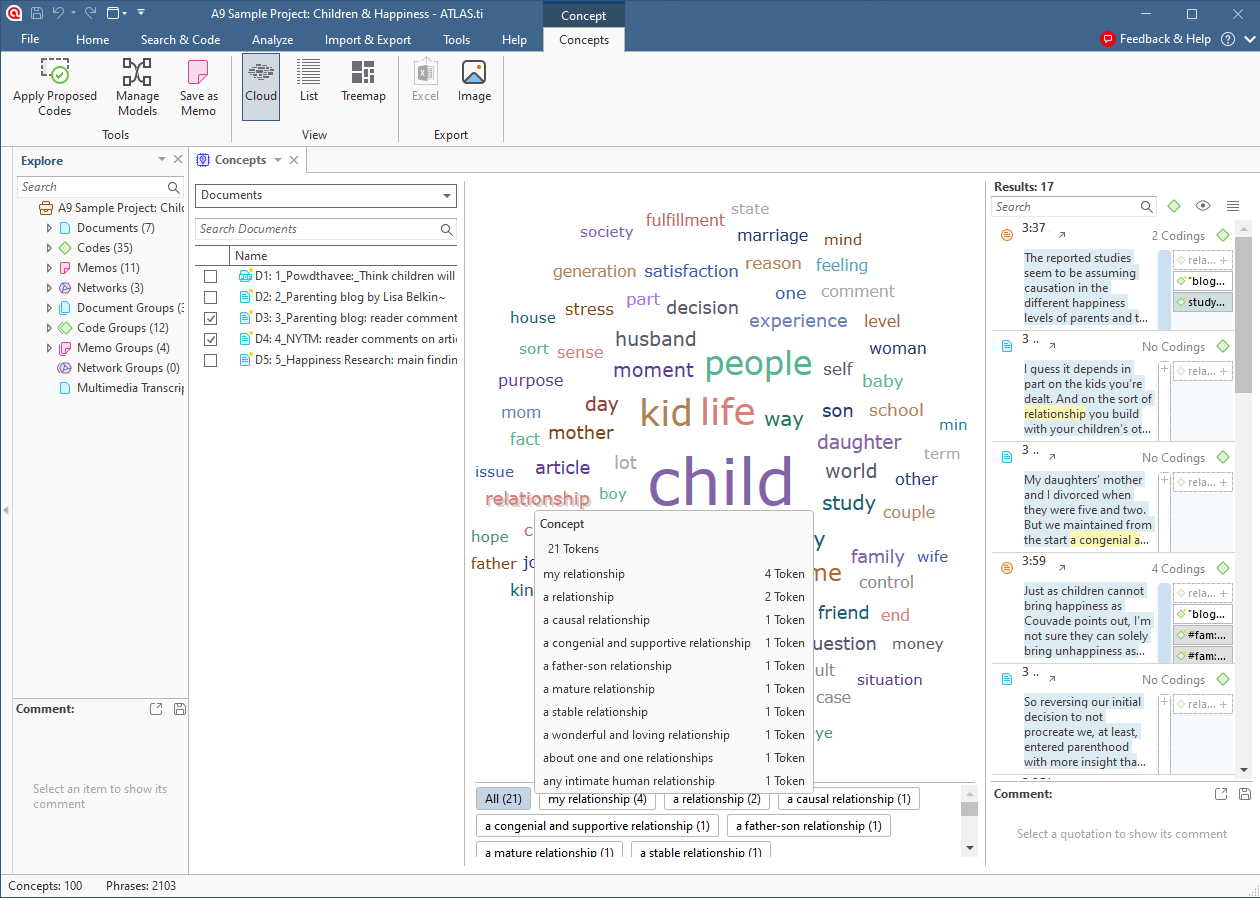
Concepts
Whereas the Word Frequencies tool can give you a straightforward statistical analysis of the most common words found in your project, the Concepts tool focuses specifically on words that represent concepts, filtering out other words such as articles and prepositions. Moreover, you can easily identify the main concepts and their sub-concepts, which encapsulate the neighboring words and phrases associated with the main concept. Machine learning can look at text and identify which words belong together, affecting the nuance of language. After all, "driving test" and "test drive" have very different meanings, so it might be important for a researcher to be able to distinguish which phrases appear more frequently in their research project.
ATLAS.ti's natural language processing can create a visualization based on frequently occurring concepts in your data. By clicking over hovering over each item in the resulting word cloud, researchers can examine what other words are connected to that word. This can help you get a bird's eye view of the topics embedded in the data so you can code the relevant text while filtering out data that uses the same words but explores unrelated topics.
Sentiment Analysis with AI
Text analysis can uncover not just meaning but also positive or negative feelings in words and sentences. Natural language processing can identify sentiments embedded in text that may be useful in extracting insights from your data.
The Sentiment Analysis tool in ATLAS.ti can apply sentiment codes to your data. AI and machine learning models are applied to the data to determine if the text is positive, negative, or neutral in nature. As with the AI Coding tool, Sentiment Analysis returns a proposed set of codes that you can apply in full or only in selected parts of your data.
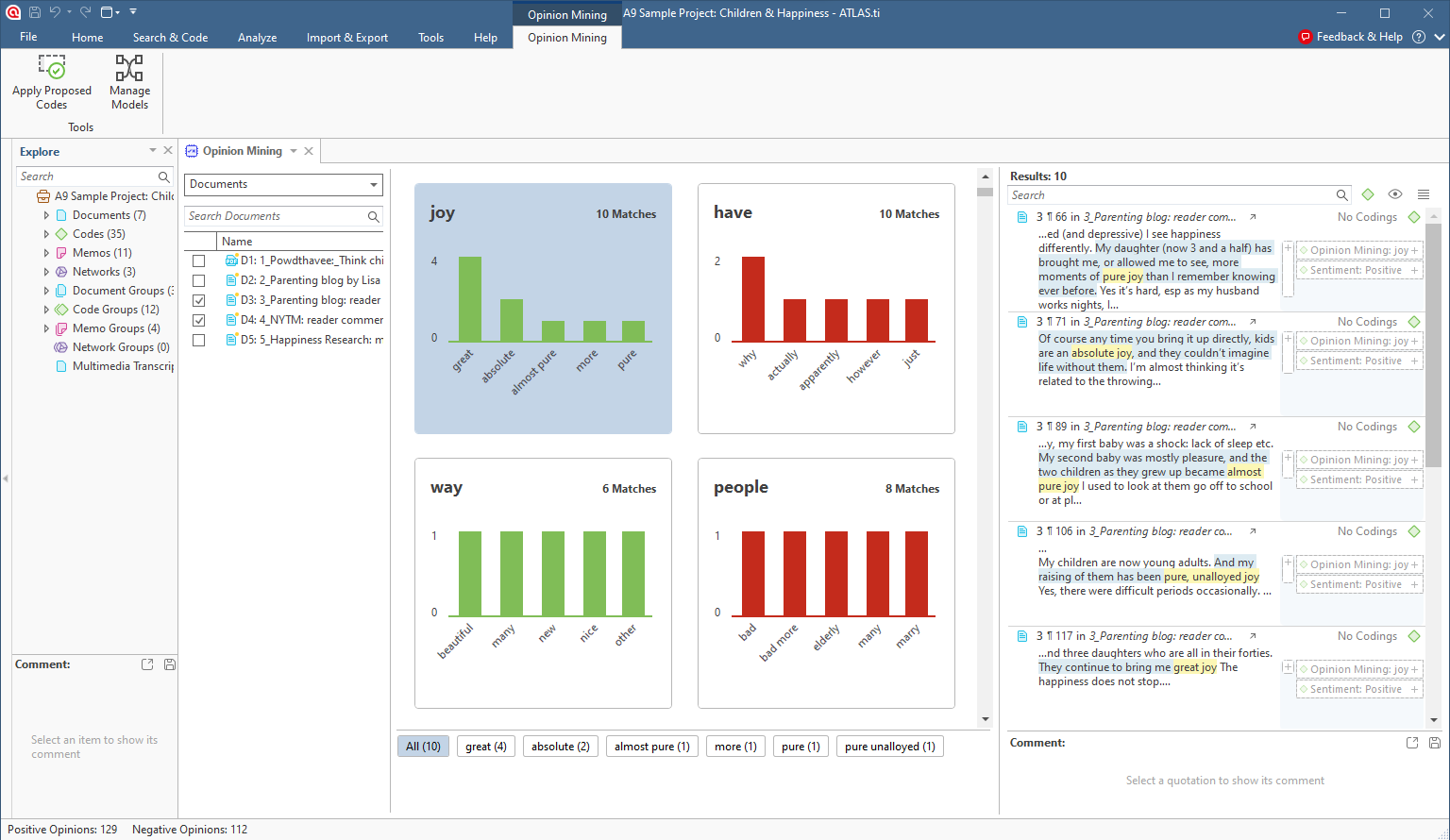
Opinion Mining
As an extension of Sentiment Analysis and Concepts, the Opinion Mining tool can automate the process of producing insightful visualizations based on an interpretive analysis of the data. The Opinion Mining tool can identify commonly used words in key phrases, visualize descriptive statistics of the words associated with each term, and propose sentiment and opinion codes for all relevant quotations. This makes it easy to understand not only what is being talked about in your data but also how people feel about that specific thing.
Named Entity Recognition
Qualitative research often depends on identifying relationships between social phenomena and different groups of people, locations, or organizations. For example, you may want to analyze data on positive and negative sentiments regarding a set of countries. This requires the use of sentiment codes as produced in Sentiment Analysis as well as descriptive codes that Named Entity Recognition can provide.
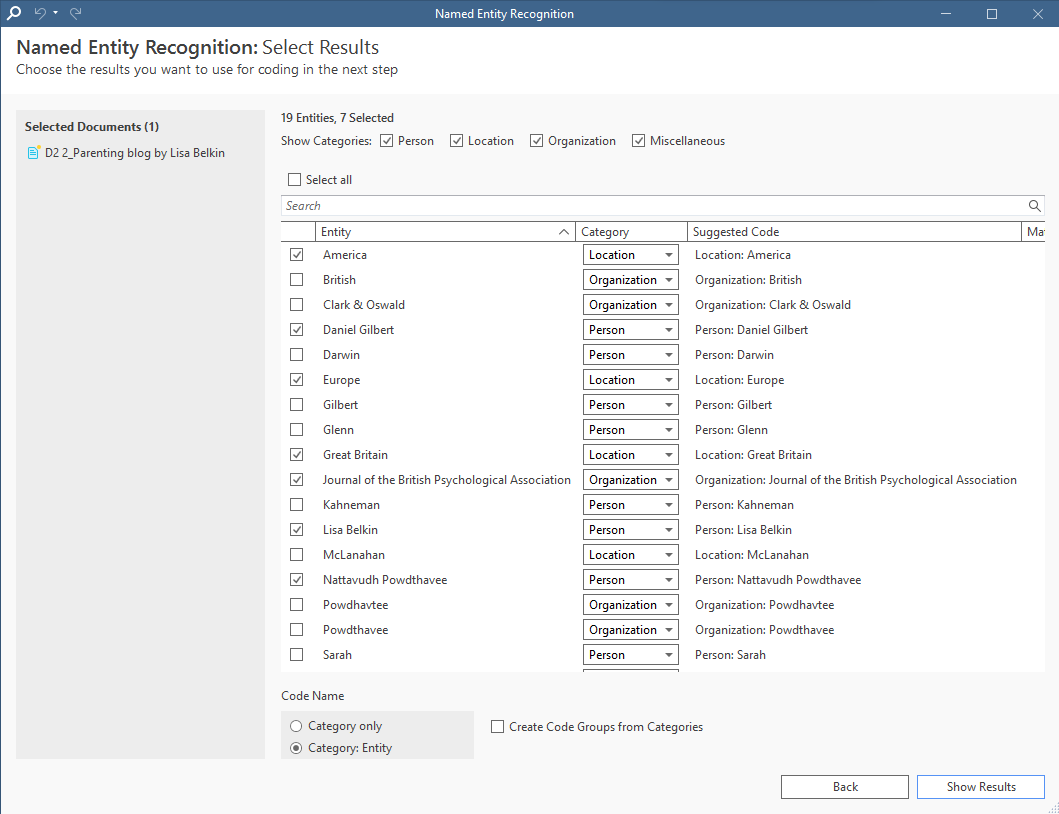
Machine learning capabilities in Named Entity Recognition can identify the names of places, people, or groups and can suggest codes for data segments that mention these names. After that, the Co-Occurrence Analysis tool can cross-tabulate these codes with your sentiment codes to identify the nature of the sentiments expressed in the data that explores a particular named entity.
Applications for ATLAS.ti's AI tools
AI and machine learning sound cool, but they are only beneficial when they are applied with intentional objectives to your data analysis. What are you looking to do with the insights you uncover from your data? What is the research inquiry you are pursuing? How can artificial intelligence and machine learning assist you with the objectives of your research?
Data analysis can have any of several objectives depending on the research inquiry. Let's look at a few of the most common types of data analysis as well as an explanation on how AI, machine learning, and ATLAS.ti can achieve your desired analysis.
Causal analysis
A central objective of data analysis is identifying key relationships between different phenomena. If you have coded the various aspects of your data with short codes for later summary, then you can use ATLAS.ti's Co-Occurrence Analysis tool to determine whether codes and the phenomena they represent intersect each other, thus signaling the possibility of a substantive relationship. Co-Occurrence Analysis alone cannot prove causality, but it can lay the foundation for a deeper analysis based on correlation.
ATLAS.ti's AI Coding tool also automates the Co-Occurrence Analysis process as AI analytics embedded in the tool can determine potential relationships between different, automatically-generated codes. Because of this automation, the AI Coding tool can identify code relationships that you may not be aware of, giving you a greater understanding of your data.
Descriptive analysis
Statistical models and quantitative analysis aren't always the most appropriate approaches in research. Especially when inquiring about social phenomena that can't be quantified, descriptive analysis aims to identify key aspects that can define a concept.
Consider the topic of happiness associated with raising children. A descriptive analysis can define the concept of happiness by the aspects of happiness that people might talk about.
The Concepts tool is a good starting point when processing a set of social media data or interview transcripts. Using this tool, a descriptive analysis can seek out phrases that people use when discussing happiness and raising children. Codes applied to those phrases through Concepts can be grouped together using category codes, smart codes, and/or code groups to gather a sense of the larger themes apparently relevant to the topic of happiness.
Diagnostic analysis
Calls for action in solving a problem can arise from negative perceptions of a particular aspect of a topic or phenomenon. For example, a market research study might be interested in increasing customer satisfaction of a product that is struggling in the market. Are customers dissatisfied with the price, the effectiveness, or the design of the product?
To address this question, the researcher can conduct Sentiment Analysis on interviews and focus groups asking current and prospective customers about the product. Diagnosing the problem in this context can be as easy as the AI analytics in Sentiment Analysis identifying negative sentiments and coding the associated quotations in terms of the aspects of customer satisfaction mentioned above (i.e., "price", "effectiveness", and "design"). A simple analysis of the frequencies associated with each aspect can provide a clearer sense of where the product struggles, pointing the business to where the product can be improved.
More information about AI and ATLAS.ti
ATLAS.ti has devoted significant time and resources developing applications with AI capabilities to aid researchers in analyzing data. To learn more about what AI-powered tools we offer, visit the ATLAS.ti AI Lab.

Human decision
It's important to emphasize that each ATLAS.ti's AI-powered research tool can only suggest codes for your research project. In any AI qualitative analysis, AI and machine learning provide the competitive advantage in analyzing data faster, but human input is necessary to confirm the possible insights that AI uncovers.
As the data analyst, you have complete control of your project and your data. ATLAS.ti tools using AI and machine learning give users the chance to review suggestions before approving or rejecting them.
Member checking
If you are dealing with data from interviews, focus groups, or any other form of data collection involving spoken or written input from research participants, the role of AI analytics is to summarize what those research participants say or write through automated codes.
Automated or otherwise, the qualitative data analysis process in smaller-scale research projects can benefit from a concept called member checking. If you have continued access to your research participants after data collection, it might be helpful to present your analysis to them and confirm the extent to which the analysis reflects their perspectives and opinions. This confirmation process, while potentially time-consuming, can ensure that the analysis is protected against critiques of bias or lack of research rigor.
AI and data protection
The AI Coding tool takes advantage of AI analytics models found online, meaning that data is processed online. This can create privacy concerns for social science researchers and their research participants.
Any data collection involving the gathering of perspectives from research participants should ensure informed consent about how their data is used and protected so that bad actors don't have access to any personal information. With any AI-powered research tool in ATLAS.ti, you can rest assured that all your project data is protected locally on your devices and encrypted when stored in our cloud-based project library or processed through OpenAI's models on their servers.
