
Document Analysis of PDF Files | Techniques & Tools

- Introduction
- What is document analysis?
- Uses for document analysis of PDF files
- Conducting a PDF file analysis
Introduction
Document analysis is a useful approach to qualitative research when you want to draw meaning from or identify patterns within a particular genre of writing or a set of documents. Oftentimes, document analysis looks at PDF files as a central source of data.
As a result, this article will look at the particular things that researchers should keep in mind when analyzing PDFs in research. This includes what document analysis is, what makes PDFs an important source of data, and how to analyze them.

What is document analysis?
Document analysis is exactly as the name suggests: looking at documents to uncover meanings and identify patterns. A document analysis is either its own standalone study, oftentimes to understand how texts are constructed or how knowledge is communicated, or a part of a broader study that triangulates findings from other methodologies such as interviews and surveys.
A basic document analysis can examine what meaning is being constructed within a genre of documents. For example, the collection of newspaper articles surrounding a notable news event can reveal what information is emphasized or overlooked or what stance writers take when they produce newspaper articles.
By conducting this analysis, researchers can contrast the patterns found in newspaper articles with those found in history books or documentaries, each of which has potentially different ways of looking at the same news event. Moreover, the study can break down a set of newspaper articles by language or region to get a more detailed sense of the differences in perspectives when reporting on the same story.
Documents can also be analyzed for their structure. Genres like recipes and menus each have a set of elements that are commonly expected, but every document within its given genre is bound to have some variations.
A recipe, for example, will have sections for ingredients, steps, and suggestions for best results. But what if you're looking at a more health-conscious cookbook? You might find recipes with nutritional information or a separate section devoted to healthy substitutions (e.g., cauliflower rice instead of bread or regular rice).
You can use this analysis to examine how recipes are conveyed in cooking shows, YouTube videos, and even blog articles, which might present a different structure to presenting information than a traditional cookbook.
Recipe blogs, for instance, tend to be far heavier in text than cookbooks for the purpose of keeping users on the website longer to generate more revenue. As a result, you might learn more information about a particular dish or a genre of cooking when reading a blog because of the structural requirements for what is considered a good online source for recipes.
By analyzing recipes across different sources and subcultures, you can gain a more holistic sense of how the genre is perceived by authors of its documents and propose a more robust framework for understanding the patterns within the genre.
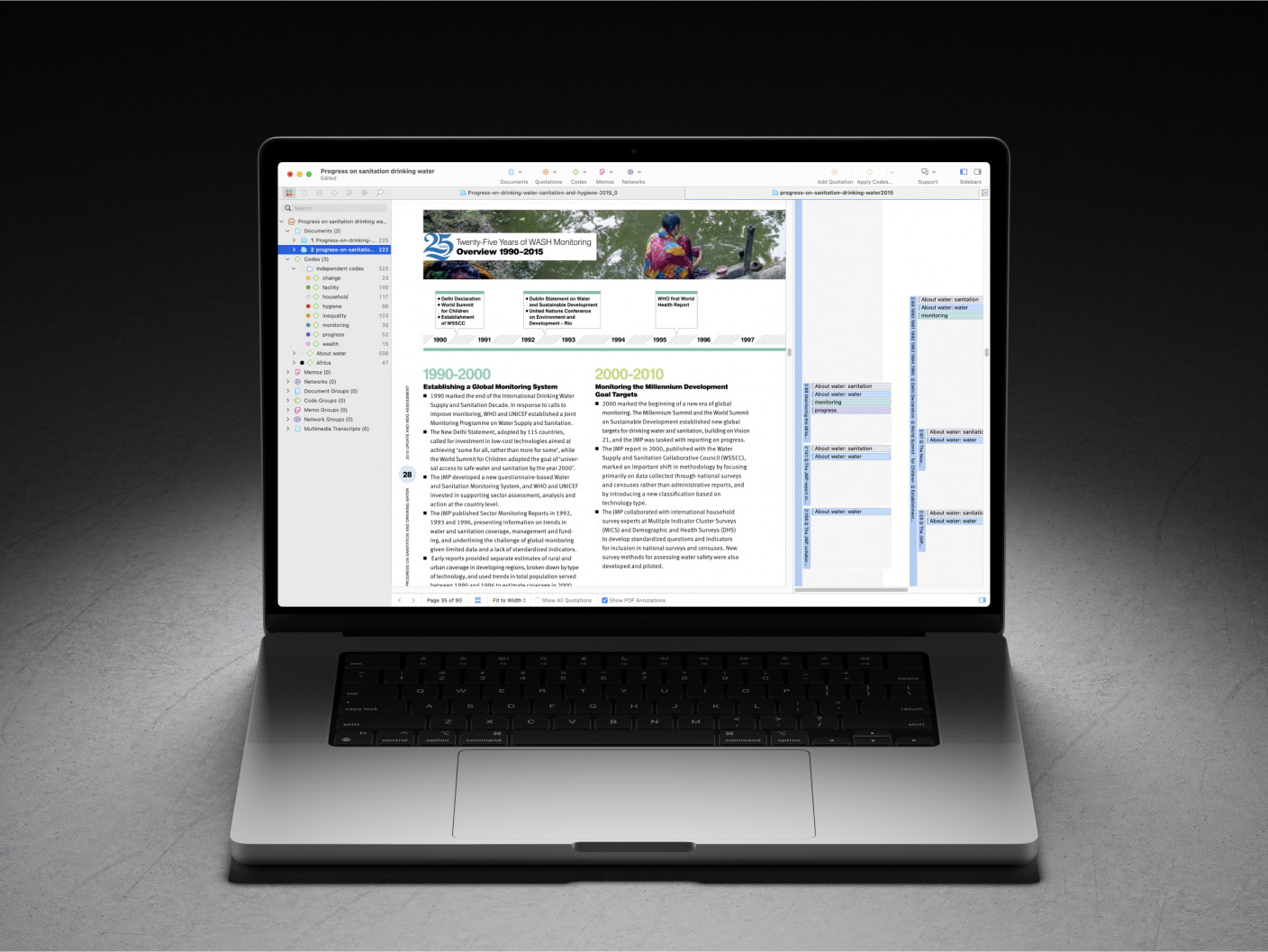
Uses for document analysis of PDF files
A PDF file holds a special place in digital literacies. The PDF format was created to provide a way to universally share documents, no matter what device or software people used or how the document was designed. Word processors read and write files in different ways but a PDF file generally looks the same regardless of who opens it.
PDF files make up a vast source of data online, with the use of the PDF format providing a sense that the information contained within any given PDF file is official and somewhat permanent. It is a mainstay when it comes to things such as paperwork, journal articles, or any other genre that benefits from the presence of a lasting record.
Think about how websites like Wikipedia are easy to change and how often news outlets update the latest headlines throughout the day. Blogs are updated on a continual basis and include dynamic elements such as advertising and comment sections. Online services like Google Docs create files for everyone to share and edit, giving the text an almost ephemeral, always changing quality if enough people have access to it.
PDFs, on the other hand, can give you the impression that they don't change, or at least seldom change. Imagine that it's time to file your taxes, with all the rules and complexities involved in filling out the paperwork. A blog or a web search can give you some preliminary information on how to get your taxes done, but you might be more likely to rely on the PDF of a user guide on a government website for the final word.
In another example, what do you do when you're checking out restaurants online? Comments on a review website might tell you what kind of food they serve, but that information might be outdated and the dish you're looking for might not be there when you book your reservation. On the other hand, if the restaurant's website has a PDF of their menu posted online, you might be more confident about what they serve and can then decide whether to go there or not.
For any number of reasons, it's more common to think of PDF files as a static source of knowledge, and that affects the way we think about the information contained within. As a result, this can have a profound influence on how you collect and analyze data from PDF files.
Conducting a PDF file analysis
A document analysis of PDF files is manageable once you consider a number of important aspects, beginning with research design. Consider what kind of PDF data you're looking for and why it's important to use PDF files as the core of your data and not, for example, plain text files or multimedia. Does the way that people read and understand the data from PDF files differ from when they look at other texts? Are there certain kinds of information that are only or primarily available in PDF files?
Use these considerations to think about your analytical approach. Are you looking to understand the overall meaning from a set of PDF documents or are you looking to read between the lines to examine the structure of those documents? If it's the former, then a thematic analysis will be appropriate for your research. Otherwise, consider a genre analysis or narrative analysis to get at the structure or intention of the data.
In terms of data collection, think about narrowing your search of PDF files to a specific genre or part of the Internet for the sake of conducting rigorous research. For example, if you're looking at information about municipal services in Japan that foreigners living in Japan might look for, then a narrow data set of "English-language PDF files from Japanese government websites" is a good set of document data to collect.
When you're looking at genres, then your data collection should target a specific style or styles codified in PDFs. Articles in scholarly journals follow a specific format when converted to PDFs, but do they look different depending on the research discipline or field? As a result, it might be worth collecting PDF articles in various research fields from the hard sciences to the humanities to help identify any important differences.
Data analysis can be made easier if the PDF files are text-searchable. Older PDFs can be more like photocopies of traditional texts, making text searches and, thus, any content analysis or other text-based approach challenging. In that case, you might want to consider using an OCR program that converts image-based PDFs into searchable documents before incorporating them into your analysis.
Once you've collected and organized your data set, it's simply a matter of conducting the document analysis, which includes coding the data based on your research question and then generating findings from an understanding of how the codes manifest in the data. Your document analysis can also incorporate a content analysis of the words and phrases employed, a sentiment analysis determining the extent that ideas are expressed positively or negatively, or even a diagrammatic analysis of the structure of PDF documents to identify patterns accordingly.
