
How to perform automatic focus group coding using ATLAS.ti Desktop


- Introduction
- Focus groups and possible applications of focus group coding
- How to carry out focus group coding
- Wrapping up
- How to cite "How to perform automatic focus group coding using ATLAS.ti Desktop"
Introduction
ATLAS.ti can automatically detect and code each passage of speech in your focus group transcription, so you can quickly and easily recollect each participant's responses and make comparisons. ATLAS.ti can also automatically associate multiple codes at a time, so you can take advantage of preparing and analyse your focus group data in whichever way you want to.
Focus groups and possible applications of focus group coding
What is a focus group? Conducting focus group discussions is a method of data collection whereby data are collected from multiple participants simultaneously. Focus groups involve a relatively unstructured but guided discussion focused on a topic of interest. The researcher only moderates the debate because the aim is to foster a natural and free-flowing conversation. Focus groups are an increasingly popular way to collect data from participants nowadays. Although this was initially developed as a social science method and many health researchers used it, it is now rapidly growing. It has spread to political research, market research, and more.
So, typically when we work in ATLAS.ti, we add our data in multiple documents. For example, we will add ten interview transcripts to our ATLAS.ti project if we have conducted ten interviews. We can then group these ten interviews according to each participant's sex, age, role, and so on. By grouping documents according to these different factors, we can easily compare and contrast across our participants. What, then, happens with focus group data? Well, things become a bit more “complicated” since we have all of the participants' information in one single document. Therefore, we cannot group each participant according to our different variables of interest (such as age, sex, role, etc.). For example, a single focus group often has a mix of male and female participants; the participants might be in different age groups, have different backgrounds, etc. Thus, adding an entire focus group file to a document group of gender: male or gender: female is not practical.
Therefore, focus group data need to be treated differently: each speaker unit needs to be identified and coded. The developers of ATLAS.ti foresaw this need, so they developed a dedicated focus group coding tool to facilitate the analysis of rich focus group data.

How to carry out focus group coding
To prepare the focus group transcript, we need to ensure that each speaker is indicated by their name, pseudonym, or some abbreviation, followed by a colon (“:”). For example, your transcript may look like this:
Alex: I don’t know, I’m the sort, I don’t really struggle making friends cos everyone tells me I’ve got a big mouth, and I don’t stop talking [laughs] …
Tom: So is that how, is that how you met just, just through you striking up a conversation?
Deb: I’m trying to think exactly [laughs]. I think that’s what it was; we were both in the same research methods class …
ATLAS.ti will automatically code your focus group data by searching for any colons in the transcript. It is also helpful to start each speaker or passage of speech on a new line in the transcript. For readability, we recommend adding an empty line after each speaker unit. Apart from that, you can follow whichever transcription protocol you prefer. And remember, consistency is vital for any quality transcription!
With your transcript ready, you can import it into ATLAS.ti as a regular document. Open your transcript and click on the “Focus group coding" option, or right-click on the document in the Project Navigator and select the option from the context menu.
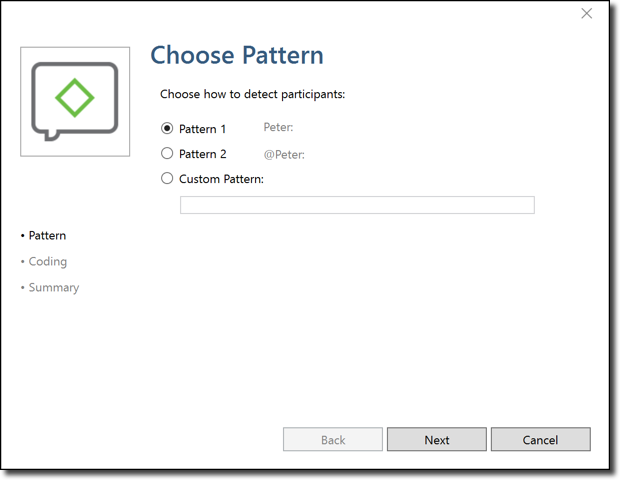
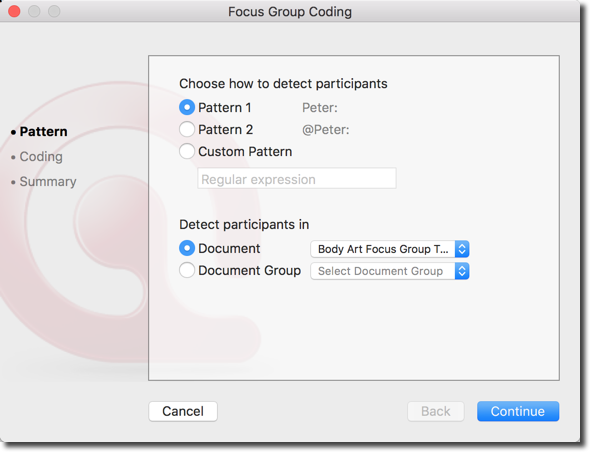
The focus group coding window will open. You can select which pattern you followed for identifying the speakers in your transcription. If you followed the example above, you can select Pattern 1.
ATLAS.ti now shows all the speakers (or units of speech) that it identified. You can write the name of the code(s) you would like to associate to each speaker on the righthand side. You can enter more than one code name for each speaker/unit of speech by writing the codes names separated by a semicolon (“;”). For example, you can easily add any relevant demographic information about each participant.
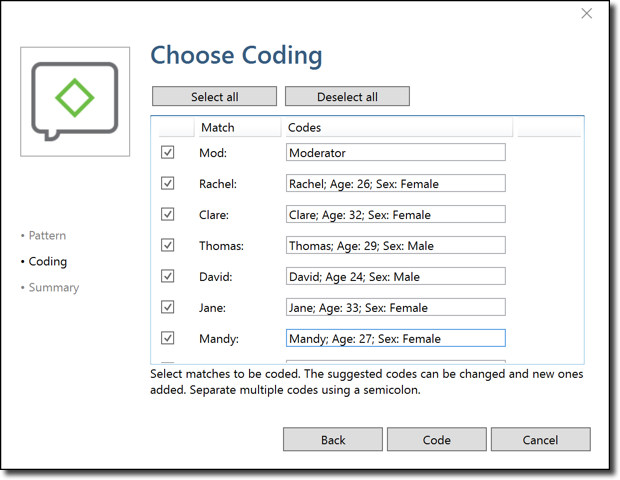
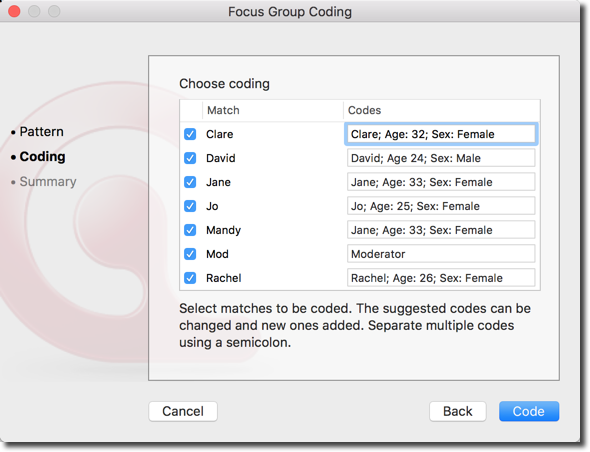
Click on “code,” and ATLAS.ti will automatically code your focus group transcript following your indications. You can now see the codings in the transcript.
You can also revise the new codings in the codes and quotations managers, from which you could also export reports of your coded quotations. With this preliminary coding done, you can proceed to read your transcript and continue coding and analysing your data in full (for deeper meanings, themes, or patterns, according to your methodology). You can also carry out content analyses (with word clouds or word lists in ATLAS.ti Windows; with the word cruncher tool in ATLAS.ti Mac). You may like to use auto-coding as well to continue quickly and easily identify keywords throughout your data. Once you have completed coding your focus group data, you can use the code co-occurrence table to compare the responses of your participants. You can also visually explore and present your findings in networks. If you want to recuperate quotations based on specific combinations of your codes, you can take advantage of the query tool.
Wrapping up
The focus group coding tool makes it easier to analyze your focus group data and draw analytic insights. As described, the tool allows you to automatically code all speaker units in your focus group data. This facilitates comparisons among your participants. We recommend that you first code your data for content using manual or other auto coding procedures. Once coding is done, auto code all speaker units. Then your data is ready for making comparisons among your participants, for instance, by using the code co-occurrence table.
How to cite "How to perform automatic focus group coding using ATLAS.ti Desktop"
APA (7th edition)
Kalpokas, N. (2022). How to perform automatic focus group coding using ATLAS.ti Desktop. ATLAS.ti Research Hub. https://atlasti.com/research-hub/how-to-perform-automatic-focus-group-coding-using-atlas-ti
MLA (9th edition)
Kalpokas, Neringa. “How to Perform Automatic Focus Group Coding Using ATLAS.ti Desktop.” ATLAS.ti Research Hub, 2022, https://atlasti.com/research-hub/how-to-perform-automatic-focus-group-coding-using-atlas-ti.
Chicago (17th edition)
Kalpokas, Neringa. “How to Perform Automatic Focus Group Coding Using ATLAS.ti Desktop.” ATLAS.ti Research Hub. 2022. https://atlasti.com/research-hub/how-to-perform-automatic-focus-group-coding-using-atlas-ti.

