
Automatisches kodieren von Fokusgruppen mit ATLAS.ti Desktop


- Einführung
- Fokusgruppen und mögliche Anwendungen der Fokusgruppenkodierung
- Wie man die Kodierung von Fokusgruppen durchführt
- Abschließend
- Wie zitiere ich "Automatisches Kodieren von Fokusgruppen mit ATLAS.ti Desktop"
Einleitung
ATLAS.ti erkennt und kodiert automatisch jede Sprachpassage in Ihrer Fokusgruppentranskription, so dass Sie die Antworten der einzelnen Teilnehmer schnell und einfach wiederfinden und vergleichen können. ATLAS.ti kann auch automatisch mehrere Kodes gleichzeitig assoziieren, so dass Sie Ihre Fokusgruppendaten auf die gewünschte Weise vorbereiten und analysieren können.
Fokusgruppen und mögliche Anwendungen der Fokusgruppen-Kodierung
Was ist eine Fokusgruppe? Die Durchführung von Fokusgruppendiskussionen ist eine Methode der Datenerhebung, bei der Daten von mehreren Teilnehmern gleichzeitig erhoben werden. Bei Fokusgruppen handelt es sich um eine relativ unstrukturierte, aber geleitete Diskussion, die sich auf ein Thema von Interesse konzentriert. Der Forscher moderiert lediglich die Debatte, da das Ziel darin besteht, ein natürliches und frei fließendes Gespräch zu fördern. Fokusgruppen sind heutzutage eine immer beliebtere Methode, um Daten von Teilnehmern zu sammeln. Obwohl sie ursprünglich als sozialwissenschaftliche Methode entwickelt wurde und viele Gesundheitsforscher sie einsetzten, nimmt sie jetzt rasch zu. Sie hat sich auf die politische Forschung, die Marktforschung und andere Bereiche ausgedehnt.
Wenn wir in ATLAS.ti arbeiten, fügen wir unsere Daten normalerweise in mehreren Dokumenten hinzu. Zum Beispiel fügen wir unserem ATLAS.ti-Projekt zehn Interview-Transkripte hinzu, wenn wir zehn Interviews geführt haben. Wir können diese zehn Interviews dann nach Geschlecht, Alter, Rolle usw. der Teilnehmer gruppieren. Indem wir die Dokumente nach diesen verschiedenen Faktoren gruppieren, können wir unsere Teilnehmer leicht vergleichen und gegenüberstellen. Was geschieht dann mit den Daten der Fokusgruppen? Nun, hier wird es etwas "komplizierter", da wir alle Informationen der Teilnehmer in einem einzigen Dokument haben. Daher können wir die einzelnen Teilnehmer nicht nach den verschiedenen Variablen, die für uns von Interesse sind (wie Alter, Geschlecht, Rolle usw.), gruppieren. Eine einzelne Fokusgruppe hat zum Beispiel oft eine Mischung aus männlichen und weiblichen Teilnehmern; die Teilnehmer können verschiedenen Altersgruppen angehören, einen unterschiedlichen Hintergrund haben, usw. Daher ist es nicht praktikabel, eine gesamte Fokusgruppendatei zu einer Dokumentgruppe von Geschlecht: männlich oder Geschlecht: weiblich hinzuzufügen.
Daher müssen Fokusgruppendaten anders behandelt werden: jede Sprechereinheit muss identifiziert und kodiert werden. Die Entwickler von ATLAS.ti haben diesen Bedarf vorausgesehen und ein spezielles Fokusgruppen-Kodierungstool entwickelt, um die Analyse von umfangreichen Fokusgruppendaten zu erleichtern.

Wie man Fokusgruppen kodiert
Zur Vorbereitung des Fokusgruppentranskripts müssen wir sicherstellen, dass jeder Sprecher mit seinem Namen, Pseudonym oder einer Abkürzung, gefolgt von einem Doppelpunkt (":"), angegeben wird. Ihr Transkript könnte zum Beispiel so aussehen:
Alex: Ich weiß nicht, ich bin der Typ, dem es nicht wirklich schwer fällt, Freunde zu finden, weil mir jeder sagt, dass ich eine große Klappe habe, und ich nicht aufhöre zu reden [lacht] ...
Tom: So habt ihr euch also kennengelernt, einfach indem ihr ein Gespräch angefangen habt?
Deb: Ich versuche, mich genau zu erinnern [lacht]. Ich glaube, das war es; wir waren beide im selben Kurs über Forschungsmethoden ...
ATLAS.ti kodiert Ihre Fokusgruppendaten automatisch, indem es nach allen Doppelpunkten im Transkript sucht. Es ist auch hilfreich, jeden Sprecher oder jede Redepassage in einer neuen Zeile des Transkripts zu beginnen. Im Interesse der Lesbarkeit empfehlen wir, nach jeder Sprechereinheit eine Leerzeile einzufügen. Abgesehen davon können Sie sich an das von Ihnen bevorzugte Transkriptionsprotokoll halten. Und denken Sie daran: Konsistenz ist das A und O einer guten Abschrift!
Wenn Ihr Transkript fertig ist, können Sie es als normales Dokument in ATLAS.ti importieren. Öffnen Sie Ihr Transkript und klicken Sie auf die Option "Focus group coding", oder klicken Sie mit der rechten Maustaste auf das Dokument im Project Navigator und wählen Sie die Option aus dem Kontextmenü.
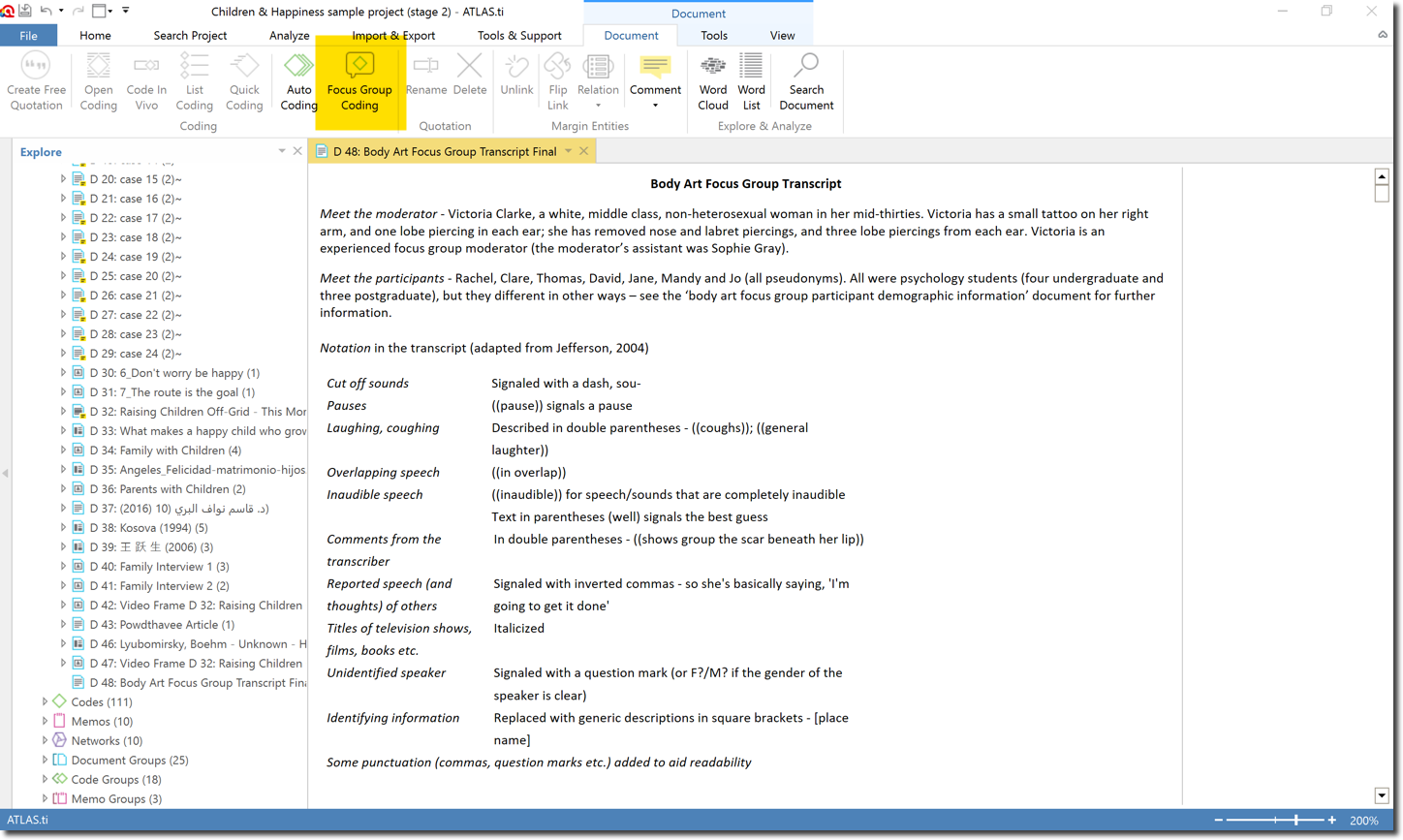
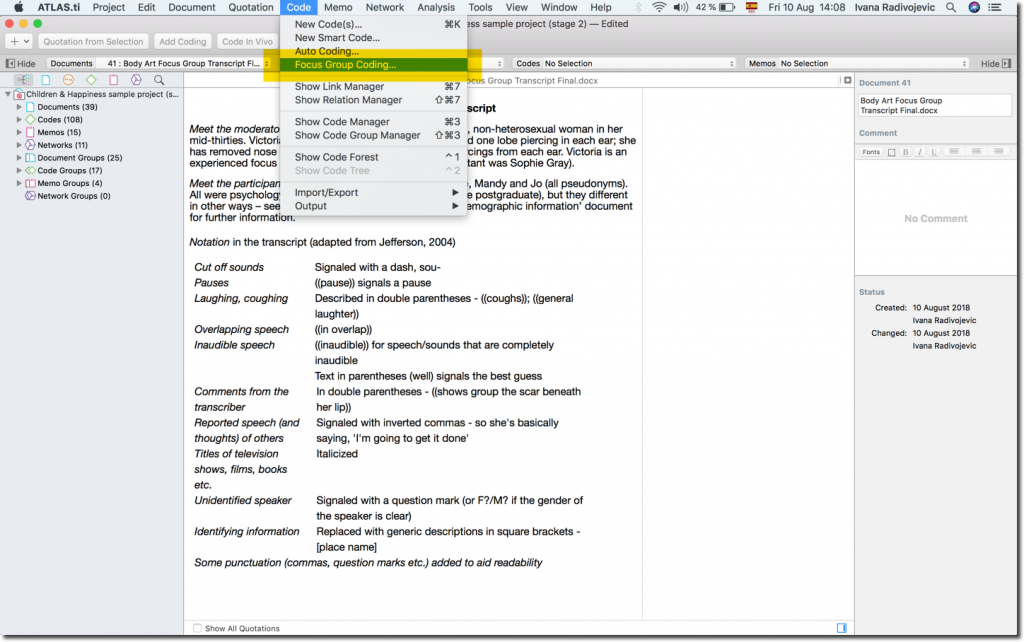
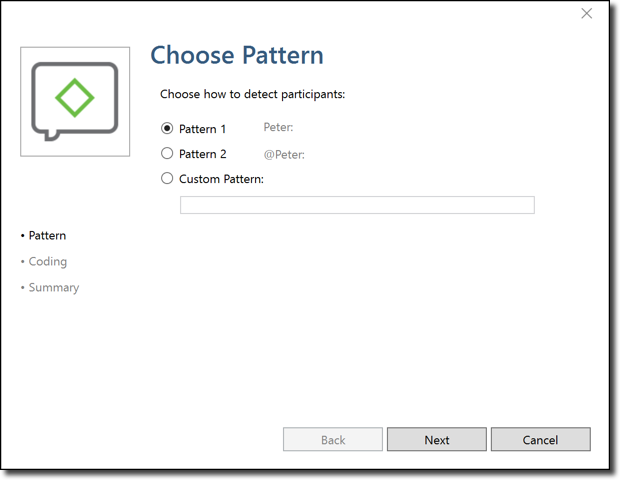
Das Fenster zur Kodierung der Fokusgruppe wird geöffnet. Sie können auswählen, nach welchem Muster Sie die Sprecher in Ihrer Transkription identifiziert haben. Wenn Sie das obige Beispiel befolgt haben, können Sie Muster 1 auswählen.
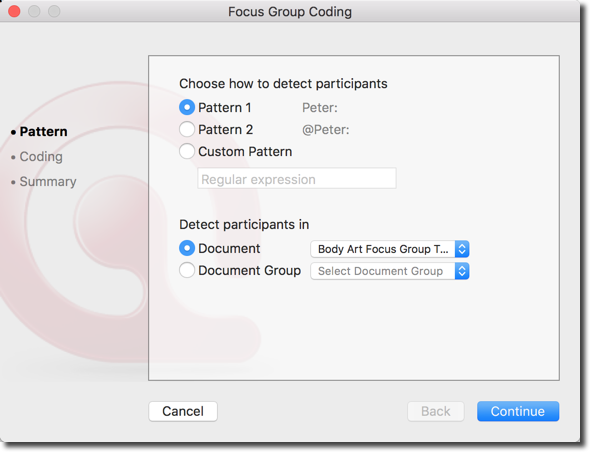
ATLAS.ti zeigt nun alle von ihm identifizierten Sprecher (oder Sprecheinheiten) an. Auf der rechten Seite können Sie den Namen des Kodes oder der Kodes, die Sie jedem Sprecher zuordnen möchten, eintragen. Sie können mehr als einen Kodenamen für jeden Sprecher/jede Sprecheinheit eingeben, indem Sie die Kodenamen durch ein Semikolon (";") getrennt schreiben. So können Sie beispielsweise problemlos alle relevanten demografischen Informationen zu jedem Teilnehmer hinzufügen.
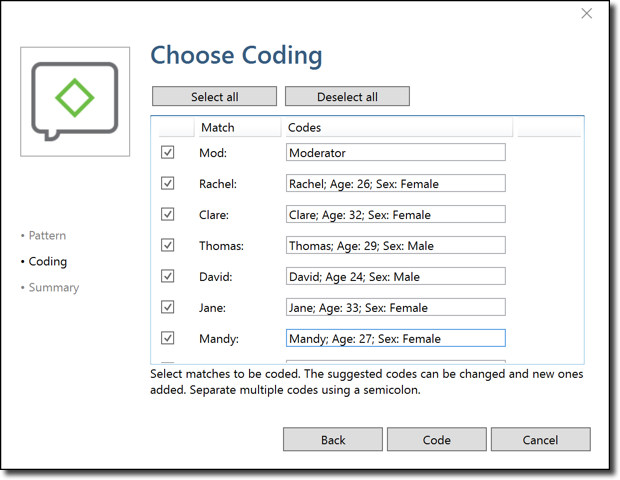
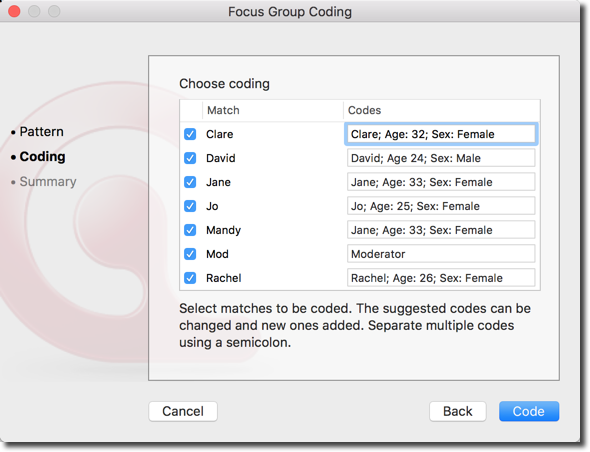
Klicken Sie auf "Kode", und ATLAS.ti kodiert Ihr Fokusgruppen-Transkript automatisch nach Ihren Angaben. Sie können nun die Kodierungen im Transkript sehen
Sie können die neuen Kodierungen auch in den Kodierungs- und Zitate-Managern überarbeiten, aus denen Sie auch Berichte über Ihre kodierten Zitate exportieren können. Nach dieser vorläufigen Kodierung können Sie Ihr Transkript lesen und mit der vollständigen Kodierung und Analyse Ihrer Daten fortfahren (auf der Suche nach tieferen Bedeutungen, Themen oder Mustern, je nach Ihrer Methodik). Sie können auch Inhaltsanalysen durchführen (mit Wortwolken oder Wortlisten in ATLAS.ti Windows; mit dem Word Cruncher Tool in ATLAS.ti Mac). Sie können auch Auto-Koding verwenden, um schnell und einfach Schlüsselwörter in Ihren Daten zu identifizieren. Sobald Sie die Kodierung Ihrer Fokusgruppen-Daten abgeschlossen haben, können Sie die Kode-Co-Occurrence-Tabelle nutzen, um die Antworten Ihrer Teilnehmer zu vergleichen. Sie können Ihre Ergebnisse auch visuell untersuchen und in Netzwerken darstellen. Wenn Sie Zitate auf der Grundlage bestimmter Kombinationen Ihrer Kodes wiederfinden möchten, können Sie das Abfragetool nutzen.
Abschließend
Das Fokusgruppen-Kodierungstool erleichtert die Analyse Ihrer Fokusgruppendaten und die Gewinnung analytischer Erkenntnisse. Wie beschrieben, können Sie mit dem Tool alle Sprechereinheiten in Ihren Fokusgruppendaten automatisch kodieren. Dies erleichtert den Vergleich zwischen Ihren Teilnehmern. Wir empfehlen Ihnen, Ihre Daten zunächst mit manuellen oder anderen Autokodierverfahren inhaltlich zu kodieren. Sobald die Kodierung abgeschlossen ist, kodieren Sie alle Sprechereinheiten automatisch. Dann sind Ihre Daten bereit für Vergleiche zwischen den Teilnehmern, z. B. mit Hilfe der Kode-Koinzidenz-Tabelle.
Wie zitiere ich "Automatisches Kodieren von Fokusgruppen mit ATLAS.ti Desktop"
APA (7. Auflage)
Kalpokas, N. (2022). Automatisches Kodieren von Fokusgruppen mit ATLAS.ti Desktop. ATLAS.ti Research Hub. Abgerufen von https://atlasti.com/research-hub/how-to-perform-automatic-focus-group-coding-using-atlas-ti
MLA (9. Auflage)
Kalpokas, Neringa. „Automatisches Kodieren von Fokusgruppen mit ATLAS.ti Desktop.“ ATLAS.ti Research Hub, 2022, https://atlasti.com/research-hub/how-to-perform-automatic-focus-group-coding-using-atlas-ti.
Chicago (17. Auflage)
Kalpokas, Neringa. „Automatisches Kodieren von Fokusgruppen mit ATLAS.ti Desktop.“ ATLAS.ti Research Hub. 2022. https://atlasti.com/research-hub/how-to-perform-automatic-focus-group-coding-using-atlas-ti.

