Der ultimative Leitfaden zur qualitativen Forschung - Teil 2: Umgang mit qualitativen Daten


- Umgang mit qualitativen Daten
- Transkripte
- Feldnotizen
- Memos
- Umfragedaten und Antworten
- Bild- und Tondaten
- Organisation von Daten
- Datenkodierung
- Kodierrahmen
- Auto- und Smart-Kodierung
- Kodes ordnen
- Qualitative Datenanalyse
- Inhaltsanalyse
- Thematische Analyse
- Narrative Forschung
- Phänomenologische Forschung
- Diskursanalyse
- Grounded Theory
- Deduktives Denken
- Induktives Schlussfolgern
- Induktives vs. deduktives Denken
- Interpretation qualitativer Daten
- Software für die qualitative Datenanalyse
- Wie zitiere ich "Der ultimative Leitfaden zur qualitativen Forschung - Teil 2"
- Thematische Analyse vs. Inhaltsanalyse
Was ist Datenauswertung? Tricks und Techniken
Rohdaten allein sind ohne Dateninterpretation für die Forschung nicht hilfreich. Die Notwendigkeit, Daten zu organisieren und zu analysieren, damit die Forschung umsetzbare Erkenntnisse hervorbringen und neues Wissen entwickeln kann, bestätigt die Bedeutung des Dateninterpretationprozesses.

Lassen Sie uns einen Blick darauf werfen, warum Dateninterpretation für den Forschungsprozess so wichtig ist, wie Sie Daten interpretieren können und wie die Werkzeuge in ATLAS.ti Ihnen helfen können, Ihre Daten auf sinnvolle Weise zu betrachten.
Die Rolle der Datenauswertung
Der Datenerhebungsprozess ist nur ein Teil der Forschung und einer, der oft viele Daten liefern kann, ohne dass sich einfache Antworten finden lassen, die Forschern oder ihrem Publikum sofort ins Auge fallen. Ein Beispiel für Daten, die einen Interpretationsprozess erfordern, ist ein Korpus oder eine große Textmenge, die einen Sprachgebrauch (z. B. Literatur, Konversation) darstellen soll. Ein Textkorpus kann Millionen von Wörtern aus geschriebenen Texten und gesprochenen Interaktionen sammeln.
Herausforderung der Dateninterpretation
Obwohl es sich um eine beeindruckende Datenmenge handelt, kann die Sichtung dieses Korpus schwierig sein. Wenn Sie versuchen, auf der Grundlage der Korpusdaten Aussagen über Sprache zu treffen, welche Daten sind für Sie nützlich? Wie können Sie irrelevante Daten von wertvollen Erkenntnissen trennen? Wie können Sie Ihr Publikum davon überzeugen, Ihre Forschung zu verstehen?
Bei der Dateninterpretation geht es darum, den Daten eine Bedeutung zuzuweisen. Es liegt in der Verantwortung des Forschers, seinem Publikum zu erklären und es davon zu überzeugen, wie er die Daten sieht und welche Erkenntnisse aus seiner Interpretation gezogen werden können.
Interpretation von Rohdaten zur Gewinnung von Erkenntnissen
Unstrukturierte Daten sind alle Arten von Daten, die nicht durch eine vorher festgelegte Struktur organisiert sind oder die in ihrer rohen, natürlich vorkommenden Form vorliegen. Ohne Datenanalyse lassen sich die Daten nur schwer interpretieren, um nützliche Erkenntnisse zu gewinnen.
Bei diesen unstrukturierten Daten handelt es sich jedoch nicht immer um sinnloses Rauschen. Wie wichtig die Dateninterpretation ist, zeigt sich an Beispielen wie einem Blog mit einer Reihe von Artikeln zu einem bestimmten Thema oder einem Kochbuch mit einer Sammlung von Rezepten. Diese Texte sind nützlich und vielleicht interessant für Leser mit unterschiedlichem Hintergrund oder Wissensstand.
Dateninterpretation, beginnend mit einer Forschungsanfrage
Menschen können eine Reihe von Informationen, wie z. B. einen Blog-Artikel oder ein Rezept, auf unterschiedliche Weise lesen (einige lesen vielleicht zuerst die Zutaten, während andere zu den Anweisungen übergehen). Die Dateninterpretation begründet das Verständnis und die Berichterstattung über die Forschung in klar definierten Begriffen, so dass, selbst wenn verschiedene Wissenschaftler sich über die Forschungsergebnisse nicht einig sind, sie zumindest ein grundlegendes Verständnis darüber haben, wie die Forschung interpretiert wird.
Nehmen wir weiter an, jemand liest eine Reihe von Rezepten, um die Esskultur eines bestimmten Ortes oder einer bestimmten Gruppe von Menschen zu verstehen. Ein einfaches Rezept vermittelt diese Informationen vielleicht nicht explizit oder auf saubere Weise. Dennoch kann ein gründlicher Leser Teile jedes Rezepts in diesem Kochbuch analysieren, um die Zutaten, Werkzeuge und Methoden zu verstehen, die in dieser bestimmten Esskultur verwendet werden.
Daher kann es für Ihre Forschungsarbeit erforderlich sein, die Daten so zu reorganisieren, dass sie leichter zu interpretieren sind. Die Analyse von Daten als Teil des Interpretationsprozesses, insbesondere in der qualitativen Forschung, bedeutet, dass man nach den relevanten Daten sucht, die Daten im Hinblick auf die Erkenntnisse, die sie enthalten, zusammenfasst und alle irrelevanten Daten, die für die gegebene Forschungsfrage nicht nützlich sind, verwirft.

Schauen wir uns ein recht einfaches Verfahren an, mit dem sich Daten durch Dateninterpretation in wertvolle Erkenntnisse verwandeln lassen.
Sortieren der Daten
Denken Sie an unser vorheriges Beispiel mit einer Sammlung von Rezepten. Sie können ein Rezept in verschiedene "Datenpunkte" unterteilen, die Sie als Kategorien oder Messpunkte betrachten können. Ein Rezept kann nach Zutaten, Anweisungen oder sogar nach der Zubereitungszeit aufgeschlüsselt werden, also nach Dingen, die oft in einem Rezept stehen. Sie können Rezepte aber auch aus einem anderen Blickwinkel betrachten, indem Sie weniger beachtete Kategorien verwenden, wie z. B. die Kosten für die Herstellung des Rezepts oder die für die Zubereitung des Rezepts erforderlichen Fähigkeiten. Welche Kategorien Sie auch immer wählen, sie bestimmen, wie Sie die Daten interpretieren.
Überlegen Sie daher, was Sie untersuchen wollen, und legen Sie fest, welche Kategorien oder Messgrößen zur Analyse und zum Verständnis der Daten verwendet werden sollen. Diese Datenpunkte bilden Ihre "Eimer", um die gesammelten Daten in aussagekräftigere Informationen für die Dateninterpretation zu sortieren.
Erkennen von Trends und Mustern
Sobald Sie genügend Daten in Ihre kategorischen Bereiche sortiert haben, werden Sie vielleicht einige aufschlussreiche Muster erkennen. Nehmen wir an, Sie analysieren ein Kochbuch mit Grillrezepten auf ihren Nährwert. In diesem Fall könnten Sie eine Fülle von Rezepten mit hohem Fett- und Zuckergehalt finden, während eine Sammlung von Salatrezepten Muster von Gerichten mit wenig Kohlenhydraten ergeben könnte. Diese Muster bilden dann die Grundlage für die Beantwortung Ihrer Forschungsfrage.
Verbindungen ziehen
Die Bedeutung dieser Trends und Muster liegt nicht immer auf der Hand. Wenn Menschen die gleiche modische Kleidung tragen oder die gleiche populäre Musik hören, tun sie das vielleicht, weil die Kleidung oder die Musik wirklich gut ist oder weil sie der Masse folgen. Vielleicht versuchen sie sogar, jemanden zu beeindrucken, den sie kennen.
Wenn Sie sich die Muster in Ihren Daten ansehen, können Sie prüfen, ob die Muster übereinstimmen (oder gemeinsam auftreten), um einen Ausgangspunkt für eine Diskussion darüber zu finden, ob sie miteinander in Beziehung stehen. Unabhängig davon, ob diese Koinzidenzen in einer sinnvollen Beziehung zueinander stehen oder nur lose miteinander korreliert sind, beginnt jede Dateninterpretation von Mustern mit der Betrachtung von Mustern und Koinzidenzen innerhalb und zwischen ihnen.
Quantitative Datenauswertung
Quantitative Analyse durch statistische Methoden kommt Forschern zugute, die ein bestimmtes Phänomen messen wollen. Mit numerischen Daten lassen sich die verschiedenen Ausprägungen eines Konzepts messen, z. B. Temperatur, Geschwindigkeit, Wohlstand oder sogar akademische Leistungen.
Bei der quantitativen Datenanalyse geht es darum, die Daten so umzuordnen, dass sie leichter zu messen sind. Stellen Sie sich vor, Sie sortieren das Sparschwein eines Kindes, das voller Münzen ist, nach verschiedenen Münzsorten (z. B. Pfennig, Fünfcentstück, Groschen und Vierteldollar). Wenn diese Münzen nicht für die Messung sortiert werden, wird es schwierig, den Wert der Münzen in diesem Sparschwein effizient zu messen.
Methode zur Interpretation quantitativer Daten
Eine gute Frage zur Datenauswertung in Bezug auf das Sparschwein des Kindes könnte lauten: "Hat das Kind genug Geld gespart?" Dann muss man entscheiden, was "genug Geld" sein könnte, ob es 20, 50 oder sogar 100 Dollar sind. Sobald diese Entscheidung getroffen wurde, können Sie Ihre Frage nach der quantitativen Analyse (d. h. dem Zählen der Münzen) beantworten.
Obwohl das Zählen des Geldes im Sparschwein eines Kindes ein einfaches Beispiel ist, zeigt es doch, dass die Interpretation quantitativer Daten oft davon abhängt, dass man einen bestimmten Wert oder eine Reihe von Werten vor Augen hat, mit denen die Analyse verglichen wird. Anhand der Kalorienzahl oder der Natriummenge, die Sie für gesund halten, können Sie feststellen, ob ein bestimmtes Lebensmittel gesund ist. Gleichzeitig wird Ihr monatliches Einkommen Aufschluss darüber geben, ob Sie ein bestimmtes Produkt als billig oder teuer empfinden. In jedem Fall beginnt die Interpretation quantitativer Daten oft mit einer bestimmten Theorie oder Vorhersage, die Sie auf die Daten anwenden.
Qualitative Datenauswertung
Dateninterpretation bezieht sich auf den Prozess der Untersuchung und Überprüfung von Daten mit dem Ziel, die Aspekte eines Phänomens oder Konzepts zu beschreiben. Qualitative Forschung hat selten numerische Daten, die aus der Datenerhebung hervorgehen; stattdessen werden oft Qualitäten eines Phänomens aus dieser Forschung generiert. Vor diesem Hintergrund besteht die Aufgabe der Dateninterpretation darin, das Forschungspublikum davon zu überzeugen, welche Eigenschaften eines bestimmten Konzepts oder Phänomens von Bedeutung sind.
Es gibt zwar viele verschiedene Möglichkeiten, komplexe qualitative Daten zu analysieren, aber hier ist ein einfaches Verfahren zur Dateninterpretation, das Ihr Forschungspublikum überzeugen könnte:
- Beschreiben Sie die Daten in allen Einzelheiten - was geschieht in den Daten?
- Beschreiben Sie die Bedeutung der Daten - warum sind sie wichtig?
- Beschreiben Sie die Bedeutung - wofür kann diese Bedeutung verwendet werden?
Methode zur Interpretation qualitativer Daten
Kodierung ist nach wie vor eine der wichtigsten Methoden der Dateninterpretation in der qualitativen Forschung. Durch das Kodieren werden die Daten strukturiert, was die empirische Analyse erleichtert. Ohne diese Kodierung kann ein Forscher zwar einen Eindruck davon vermitteln, was die Daten bedeuten, ist aber möglicherweise nicht in der Lage, sein Publikum mit den ausreichenden Beweisen zu überzeugen, die strukturierte Daten liefern können.
Letztendlich wird durch die Kodierung der Umfang der gesammelten Daten reduziert, um sie handhabbarer zu machen. Anstelle von Tausenden von Zeilen mit Rohdaten kann eine effektive Kodierung ein paar Dutzend Codes hervorbringen, die analysiert auf Häufigkeit geprüft oder verwendet werden können, um kategoriale Daten entlang von Themen oder Mustern zu organisieren.
Bei der Analyse qualitativer Daten durch Kodierung werden die Daten genau betrachtet und die Datensegmente in kurzen, aber beschreibenden Sätzen zusammengefasst. Diese Sätze oder Codes können, wenn sie auf ganze Datensätze angewandt werden, dazu beitragen, die Daten so umzustrukturieren, dass eine einfachere Analyse oder eine größere Klarheit über die Bedeutung der Daten für die Forschungsuntersuchung möglich ist.
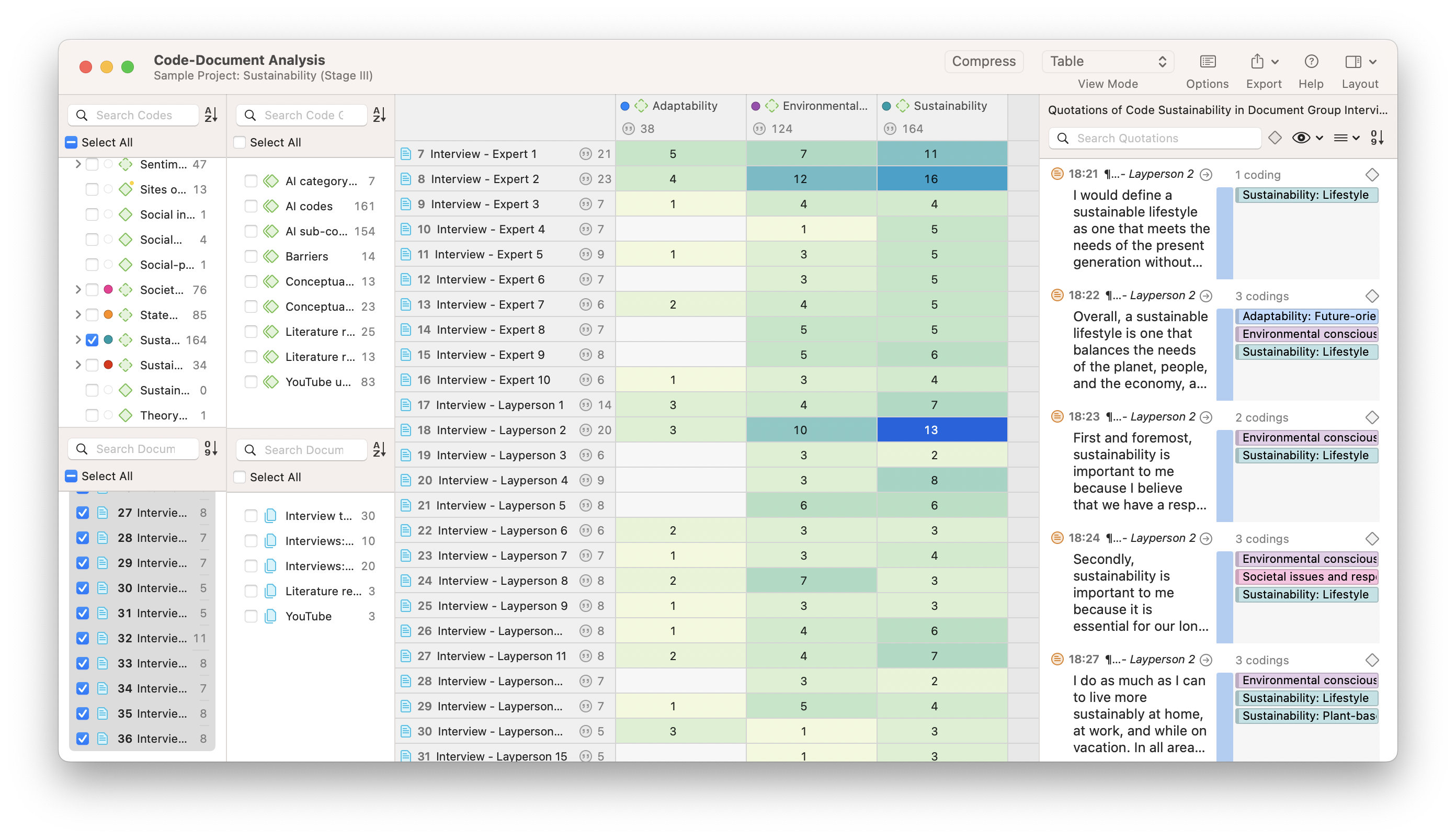
Code-Dokument-Analyse
Ein Vergleich von Datensätzen kann nützlich sein, um Muster in den Daten zu interpretieren. Die Code-Document Analyse in ATLAS.ti sucht nach Codehäufigkeiten in bestimmten Dokumenten oder Dokumentengruppen. Dies ist für viele Aufgaben nützlich, z.B. für die Interpretation von Perspektiven über mehrere Interviews oder Umfragedatensätze hinweg. Wenn jedes Dokument die Meinung einer bestimmten Person repräsentiert, wie unterscheiden sich dann die Perspektiven von Person zu Person? Das Verständnis dieser Unterschiede beginnt in diesem Fall mit der Bestimmung, wo die interpretativen Codes in Ihrem Projekt angewendet werden.
ATLAS.ti für die Datenauswertung verwenden
Software eignet sich hervorragend zur Bewältigung mechanischer Aufgaben, die andernfalls Zeit und Mühe kosten würden, die man besser in die Analyse investieren sollte. Zu solchen Aufgaben gehören die Suche nach Wörtern oder Phrasen in Dokumenten, das Ausfüllen komplizierter Abfragen, um die relevanten Informationen an einem Ort zu organisieren, und die Anwendung statistischer Methoden, die es dem Forscher erlauben, relevante Schlussfolgerungen über seine Daten zu ziehen. Was Technologie nicht kann, ist, Daten für Sie zu interpretieren. Sie kann die Daten so neu organisieren, dass Sie leichter zu einer Schlussfolgerung über die Erkenntnisse gelangen können, die Sie aus der Forschung ziehen können, aber letztendlich liegt es an Ihnen, die endgültige Entscheidung über die Bedeutung der Muster in den Daten zu treffen.
Dies gilt unabhängig davon, ob Sie qualitative oder quantitative Forschung betreiben. Ganz gleich, ob Sie versuchen, "Glück" oder "heiß" zu definieren (denn ein "heißer Tag" bedeutet für verschiedene Menschen etwas anderes, unabhängig von der Zahl, die die Temperatur angibt), es ist unweigerlich Ihre Entscheidung, die Daten zu interpretieren, die Sie erhalten, unabhängig von der Hilfe, die Ihnen ein Computer bieten kann.
Betrachten Sie eine Software zur qualitativen Datenanalyse wie ATLAS.ti als einen Assistenten, der Sie durch den Forschungsprozess begleitet, damit Sie die wichtigsten Erkenntnisse aus Ihren Daten herausfinden können, anstatt diese Erkenntnisse für Sie zu ermitteln. Dies ist besonders in den Sozialwissenschaften von Vorteil, wo menschliche Interaktion und kulturelle Praktiken subjektiv und sozial konstruiert sind, und zwar in einer Weise, die nur Menschen angemessen verstehen können. Die menschliche Interpretation von qualitativen Daten ist nicht nur unvermeidlich, sondern in den Sozialwissenschaften geradezu eine Notwendigkeit.

ATLAS.ti verfügt über eine Reihe von Werkzeugen, die die Interpretation von Daten einfacher und aufschlussreicher machen können. Diese Tools können das Reporting und die Visualisierung der Datenanalyse zu Ihrem Nutzen und dem Nutzen Ihres Forschungspublikums erleichtern.
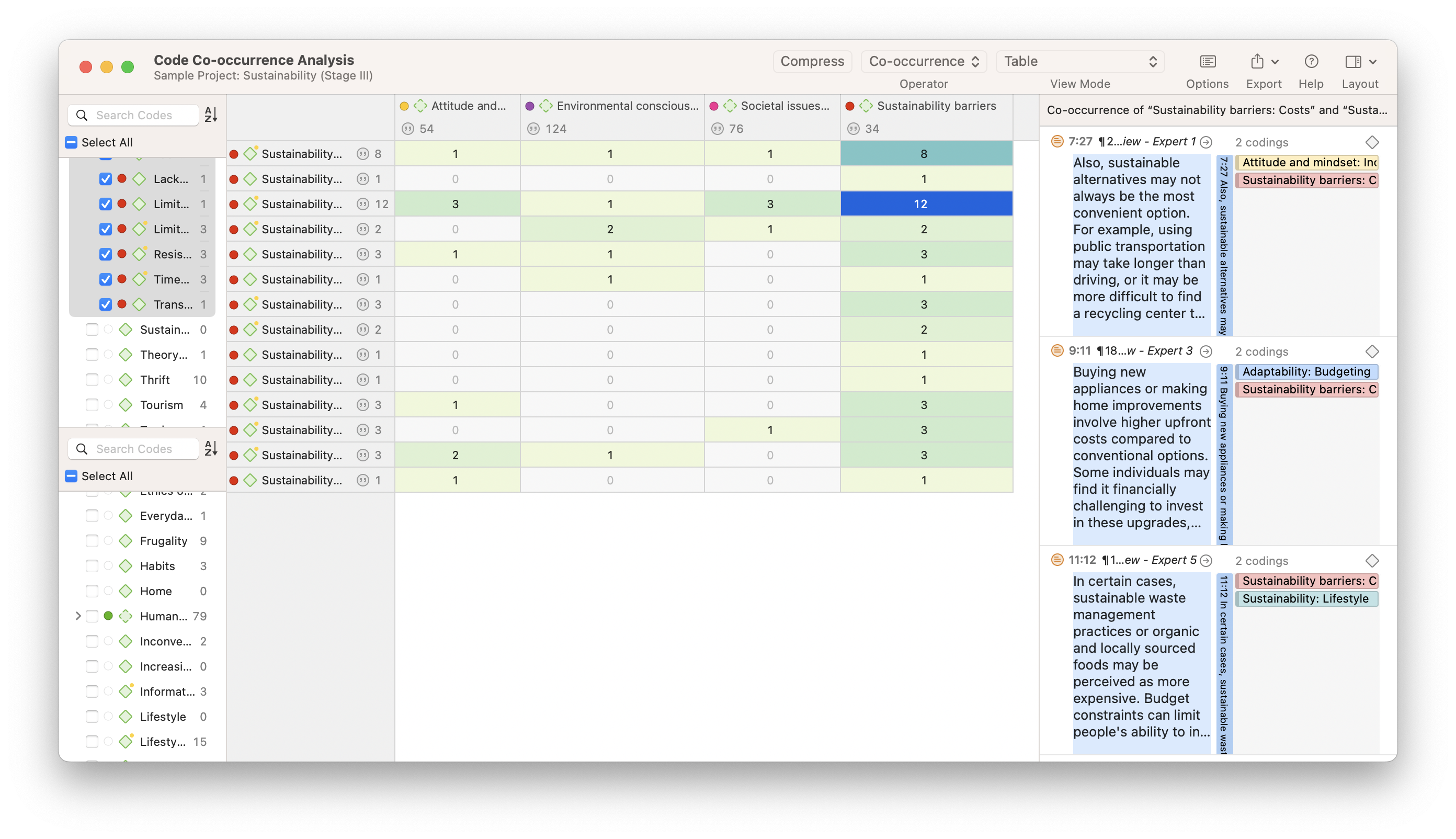
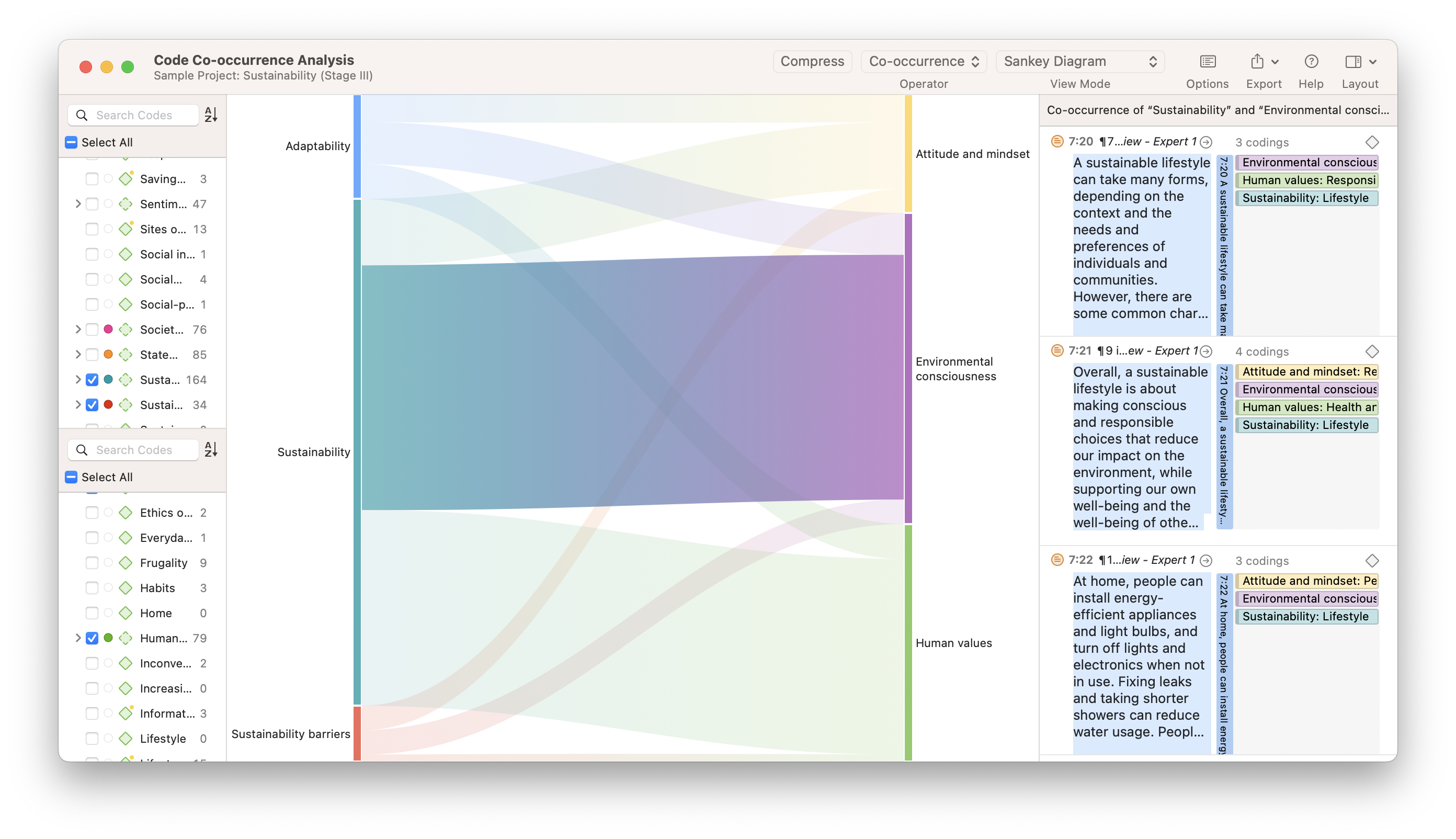
Code Co-Occurrence Analyse
Die Überlappung von Kodes in qualitativen Daten ist ein nützlicher Ausgangspunkt, um Beziehungen zwischen Phänomenen zu bestimmen. ATLAS.tis Code-Co-Occurrence-Analyse-Tool hilft Forschern, Beziehungen zwischen Codes zu identifizieren, sodass die Dateninterpretation in Bezug auf mögliche Zusammenhänge zu einem besseren Verständnis der Daten beitragen kann.
Memos
Memos sind ein wichtiger Bestandteil jeder Forschung, weshalb ATLAS.ti einen von Ihren Daten und Codes getrennten Bereich für Forschungsnotizen und Reflexionsmemos bereitstellt. Vor allem in den Sozialwissenschaften oder in anderen Bereichen, die sich mit sozial konstruierten Konzepten beschäftigen, kann ein Reflexionsmemo eine wichtige Dokumentation darüber sein, wie Forscher an der Datenerhebung und -interpretation beteiligt sind.
Mit Memos lassen sich die Analyseschritte nachvollziehen, und der gesamte Prozess ist einsehbar. Eine detaillierte Dokumentation des Datenanalyse- und Dateninterpretationsprozesses kann auch die Berichterstattung und Visualisierung von Forschungsergebnissen erleichtern, wenn es darum geht, die Forschungsergebnisse mit einem Publikum zu teilen.

Datenvisualisierung
In der Forschung besteht das Hauptziel bei der expliziten Durchführung und detaillierten Beschreibung des Datenauswertungsprozesses darin, einen aussagekräftigen und überzeugenden Forschungsbericht zu erstellen. Wo es möglich ist, profitieren Forscher von der Visualisierung ihrer Dateninterpretation, um dem Forschungspublikum die nötige Klarheit zu verschaffen, um die Forschungsergebnisse zu verstehen.
Letztendlich sollten die verschiedenen Datenanalyseverfahren, die Sie einsetzen, zu einer Form der Berichterstattung führen, bei der das Forschungspublikum die Dateninterpretation leicht verstehen kann. Andernfalls hat die Dateninterpretation keinen Wert, wenn sie vom Forschungspublikum nicht verstanden, geschweige denn akzeptiert wird.
Datenvisualisierungs-Tools in ATLAS.ti
ATLAS.ti verfügt über eine Reihe von Werkzeugen, die bei der Erstellung von Illustrationen helfen können, die dazu beitragen, Ihre Dateninterpretation für Ihr Forschungspublikum zu erklären.

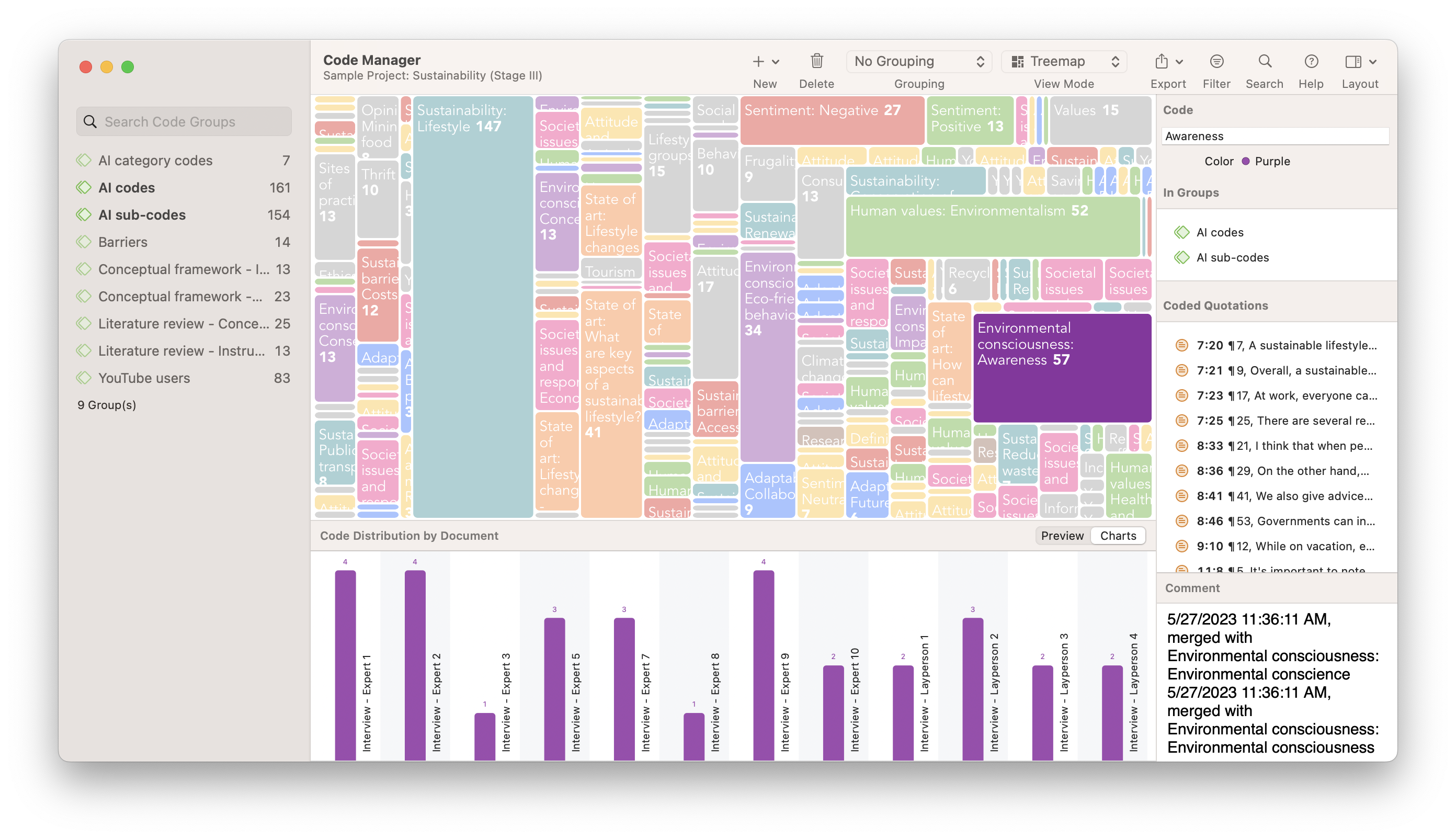
TreeMaps
Eine TreeMap Ihrer Kodes kann eine nützliche Visualisierung sein, wenn Sie eine thematische Analyse Ihrer Daten durchführen. Kodes in ATLAS.ti können mit verschiedenen Farben markiert werden, was sehr anschaulich ist, wenn Sie Farben zur Unterscheidung verschiedener Themen in Ihrer Forschung verwenden. Wenn Sie die Kodes auf Ihre Daten anwenden, nehmen die am häufigsten vorkommenden Kodes mehr Platz in der TreeMap ein, so dass Sie untersuchen können, welche Kodes und - durch die Verwendung von Farben - welche Themen mehr oder weniger offensichtlich sind und Ihnen bei der Theoriebildung helfen.
Sankey-Diagramme
Die Code-Co-Occurrence - und Code-Dokument-Analysen in ATLAS.ti können Tabellen, Grafiken und auch Sankey-Diagramme erstellen, die sich zur Visualisierung der relativen Beziehungen zwischen verschiedenen Kodes oder zwischen Kodes und Dokumenten eignen. Während die für Tabellen generierten numerischen Daten eine Geschichte Ihrer Dateninterpretation erzählen können, können die visuellen Informationen in einem Sankey-Diagramm, in dem höhere Frequenzen durch dickere Linien dargestellt werden, für Ihr Forschungspublikum besonders überzeugend sein.
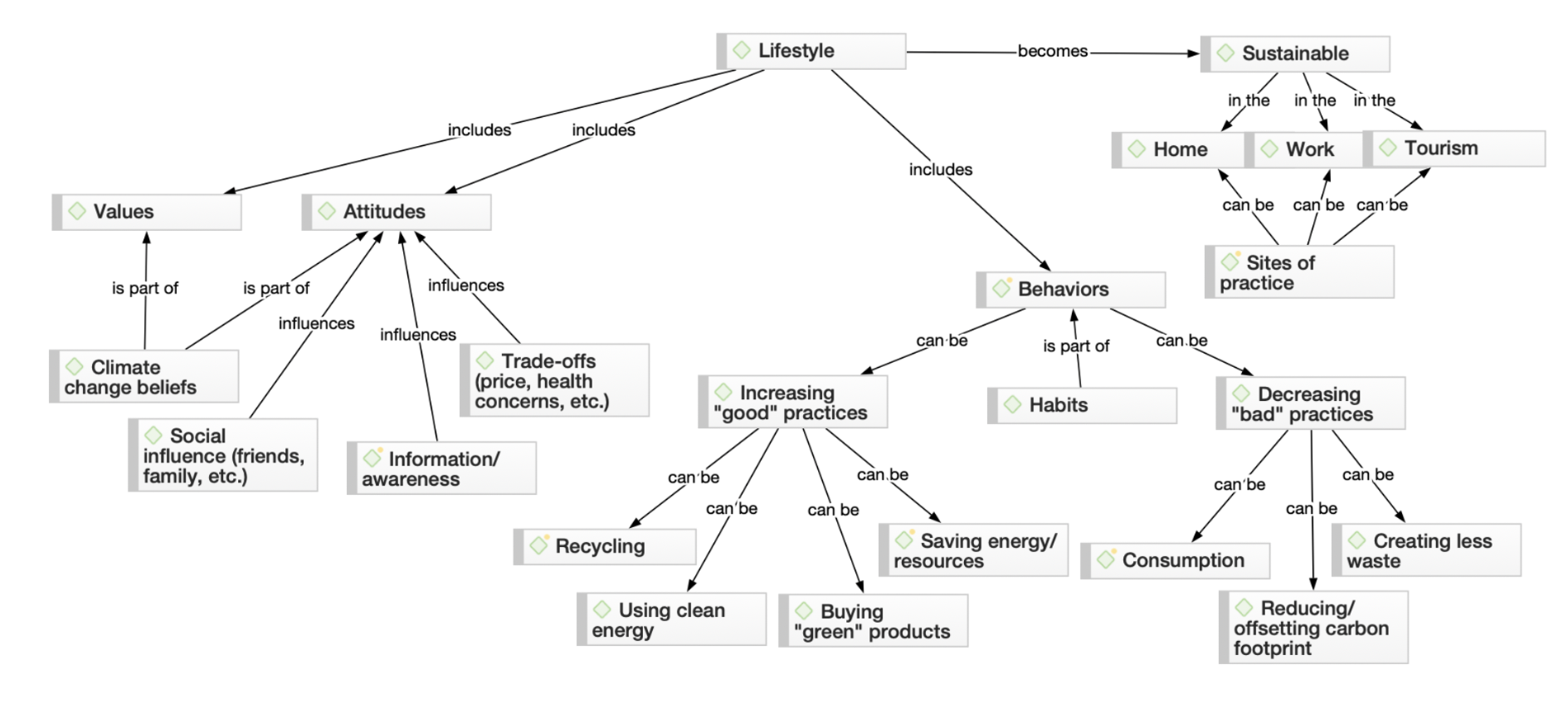
Netzwerke
Wenn es an der Zeit ist, über verwertbare Erkenntnisse zu berichten, die zu einer Theorie oder Konzeptualisierung beitragen, können Sie von einer Visualisierung der Theorie profitieren, die Sie aus Ihrer Dateninterpretation entwickelt haben. Netzwerke bestehen aus Elementen Ihres Projekts, in der Regel aus Codes, aber auch aus anderen Elementen wie Dokumenten, Codegruppen, Dokumentgruppen, Zitaten und Memos. Forscher können dann Verknüpfungen zwischen diesen Elementen definieren, um Zusammenhänge zu veranschaulichen, die sich aus Ihrer Datenauswertung ergeben.